 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVehicle Re-Identification: an Efficient Baseline Using Triplet Embedding
Jan 16, 2019

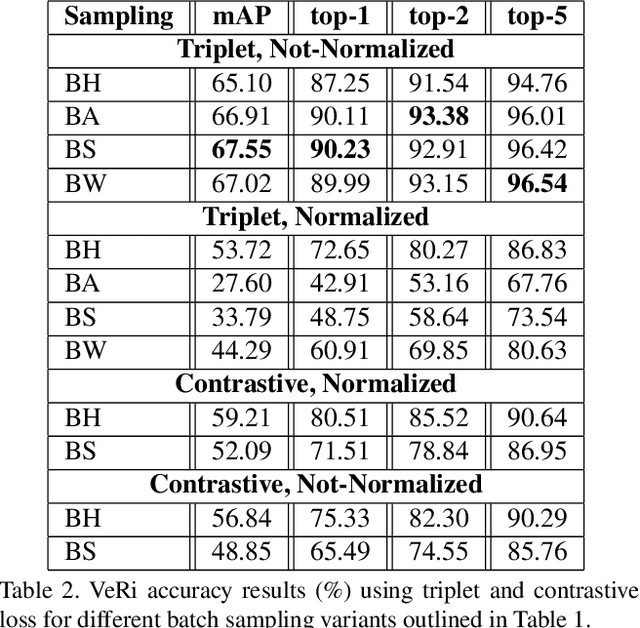

In this paper we tackle the problem of vehicle re-identification in a camera network utilizing triplet embeddings. Re-identification is the problem of matching appearances of objects across different cameras. With the proliferation of surveillance cameras enabling smart and safer cities, there is an ever-increasing need to re-identify vehicles across cameras. Typical challenges arising in smart city scenarios include variations of viewpoints, illumination and self occlusions. Most successful approaches for re-identification involve (deep) learning an embedding space such that the vehicles of same identities are projected closer to one another, compared to the vehicles representing different identities. Popular loss functions for learning an embedding (space) include contrastive or triplet loss. In this paper we provide an extensive evaluation of these losses applied to vehicle re-identification and demonstrate that using the best practices for learning embeddings outperform most of the previous approaches proposed in the vehicle re-identification literature. Compared to most existing state-of-the-art approaches, our approach is simpler and more straightforward for training utilizing only identity-level annotations, along with one of the smallest published embedding dimensions for efficient inference. Furthermore in this work we introduce a formal evaluation of a triplet sampling variant (batch sample) into the re-identification literature.