 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation and Enhanced Subdomain Adaptation Using Graph Convolutional Network for Resource-Constrained Bearing Fault Diagnosis
Jan 13, 2025



Bearing fault diagnosis under varying working conditions faces challenges, including a lack of labeled data, distribution discrepancies, and resource constraints. To address these issues, we propose a progressive knowledge distillation framework that transfers knowledge from a complex teacher model, utilizing a Graph Convolutional Network (GCN) with Autoregressive moving average (ARMA) filters, to a compact and efficient student model. To mitigate distribution discrepancies and labeling uncertainty, we introduce Enhanced Local Maximum Mean Squared Discrepancy (ELMMSD), which leverages mean and variance statistics in the Reproducing Kernel Hilbert Space (RKHS) and incorporates a priori probability distributions between labels. This approach increases the distance between clustering centers, bridges subdomain gaps, and enhances subdomain alignment reliability. Experimental results on benchmark datasets (CWRU and JNU) demonstrate that the proposed method achieves superior diagnostic accuracy while significantly reducing computational costs. Comprehensive ablation studies validate the effectiveness of each component, highlighting the robustness and adaptability of the approach across diverse working conditions.
Physics-Informed Deep Learning and Partial Transfer Learning for Bearing Fault Diagnosis in the Presence of Highly Missing Data
Jun 16, 2024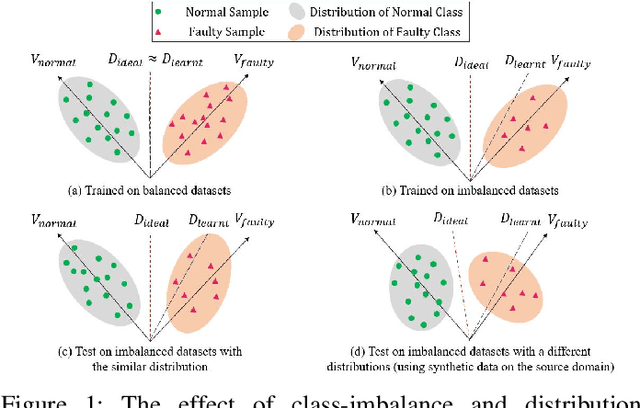



One of the most significant obstacles in bearing fault diagnosis is a lack of labeled data for various fault types. Also, sensor-acquired data frequently lack labels and have a large amount of missing data. This paper tackles these issues by presenting the PTPAI method, which uses a physics-informed deep learning-based technique to generate synthetic labeled data. Labeled synthetic data makes up the source domain, whereas unlabeled data with missing data is present in the target domain. Consequently, imbalanced class problems and partial-set fault diagnosis hurdles emerge. To address these challenges, the RF-Mixup approach is used to handle imbalanced classes. As domain adaptation strategies, the MK-MMSD and CDAN are employed to mitigate the disparity in distribution between synthetic and actual data. Furthermore, the partial-set challenge is tackled by applying weighting methods at the class and instance levels. Experimental outcomes on the CWRU and JNU datasets indicate that the proposed approach effectively addresses these problems.
A CNN-BiLSTM Model with Attention Mechanism for Earthquake Prediction
Dec 26, 2021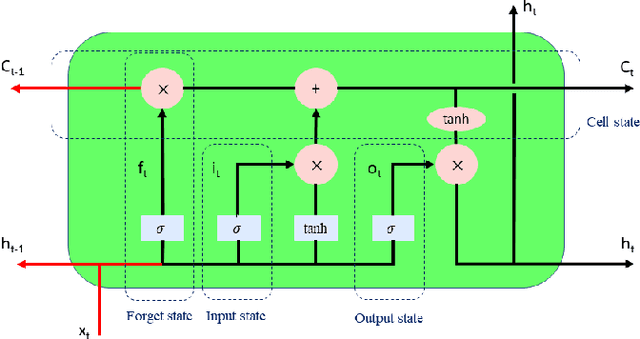
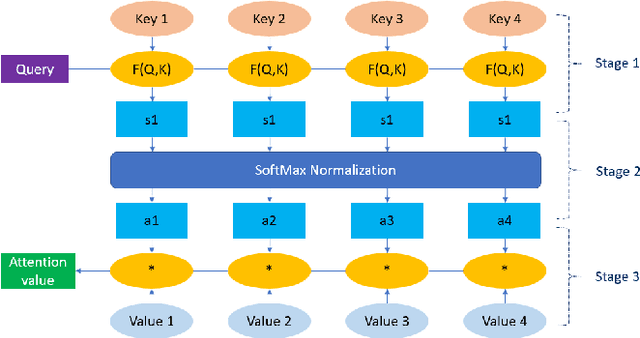
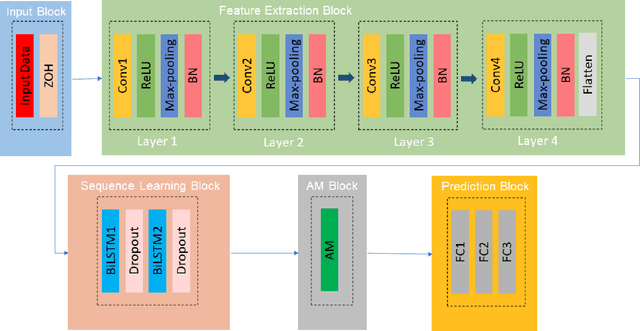
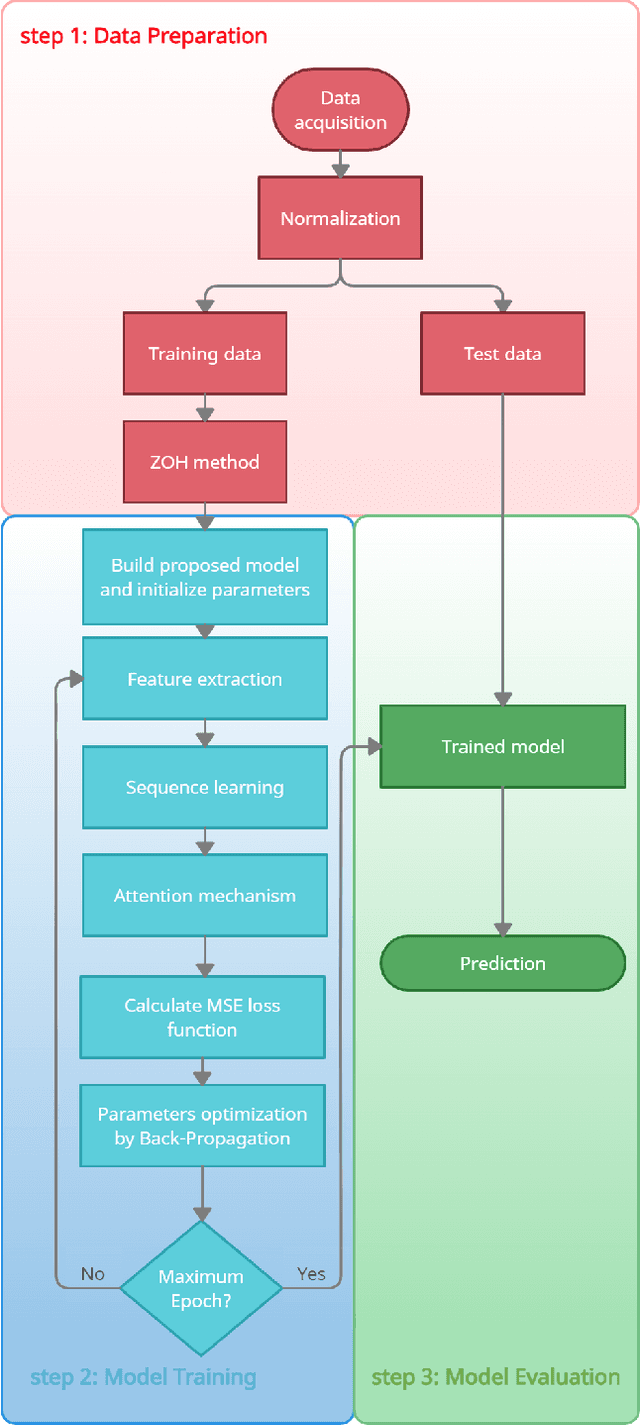
Earthquakes, as natural phenomena, have continuously caused damage and loss of human life historically. Earthquake prediction is an essential aspect of any society's plans and can increase public preparedness and reduce damage to a great extent. Nevertheless, due to the stochastic character of earthquakes and the challenge of achieving an efficient and dependable model for earthquake prediction, efforts have been insufficient thus far, and new methods are required to solve this problem. Aware of these issues, this paper proposes a novel prediction method based on attention mechanism (AM), convolution neural network (CNN), and bi-directional long short-term memory (BiLSTM) models, which can predict the number and maximum magnitude of earthquakes in each area of mainland China-based on the earthquake catalog of the region. This model takes advantage of LSTM and CNN with an attention mechanism to better focus on effective earthquake characteristics and produce more accurate predictions. Firstly, the zero-order hold technique is applied as pre-processing on earthquake data, making the model's input data more proper. Secondly, to effectively use spatial information and reduce dimensions of input data, the CNN is used to capture the spatial dependencies between earthquake data. Thirdly, the Bi-LSTM layer is employed to capture the temporal dependencies. Fourthly, the AM layer is introduced to highlight its important features to achieve better prediction performance. The results show that the proposed method has better performance and generalize ability than other prediction methods.