 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Informed Deep Learning and Partial Transfer Learning for Bearing Fault Diagnosis in the Presence of Highly Missing Data
Paper and Code
Jun 16, 2024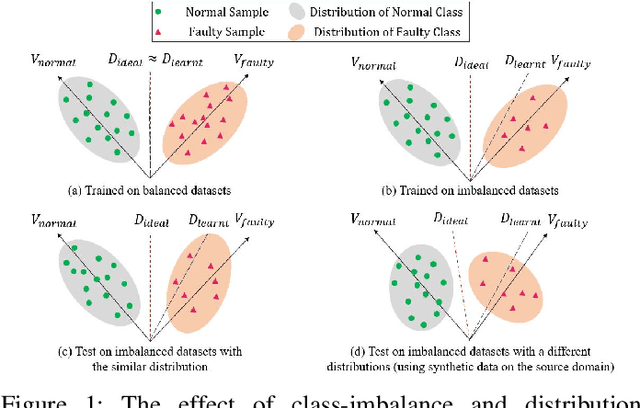



One of the most significant obstacles in bearing fault diagnosis is a lack of labeled data for various fault types. Also, sensor-acquired data frequently lack labels and have a large amount of missing data. This paper tackles these issues by presenting the PTPAI method, which uses a physics-informed deep learning-based technique to generate synthetic labeled data. Labeled synthetic data makes up the source domain, whereas unlabeled data with missing data is present in the target domain. Consequently, imbalanced class problems and partial-set fault diagnosis hurdles emerge. To address these challenges, the RF-Mixup approach is used to handle imbalanced classes. As domain adaptation strategies, the MK-MMSD and CDAN are employed to mitigate the disparity in distribution between synthetic and actual data. Furthermore, the partial-set challenge is tackled by applying weighting methods at the class and instance levels. Experimental outcomes on the CWRU and JNU datasets indicate that the proposed approach effectively addresses these problems.