 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnseen Object Reasoning with Shared Appearance Cues
Jun 21, 2024



This paper introduces an innovative approach to open world recognition (OWR), where we leverage knowledge acquired from known objects to address the recognition of previously unseen objects. The traditional method of object modeling relies on supervised learning with strict closed-set assumptions, presupposing that objects encountered during inference are already known at the training phase. However, this assumption proves inadequate for real-world scenarios due to the impracticality of accounting for the immense diversity of objects. Our hypothesis posits that object appearances can be represented as collections of "shareable" mid-level features, arranged in constellations to form object instances. By adopting this framework, we can efficiently dissect and represent both known and unknown objects in terms of their appearance cues. Our paper introduces a straightforward yet elegant method for modeling novel or unseen objects, utilizing established appearance cues and accounting for inherent uncertainties. This representation not only enables the detection of out-of-distribution objects or novel categories among unseen objects but also facilitates a deeper level of reasoning, empowering the identification of the superclass to which an unknown instance belongs. This novel approach holds promise for advancing open world recognition in diverse applications.
Objects as Spatio-Temporal 2.5D points
Dec 07, 2022

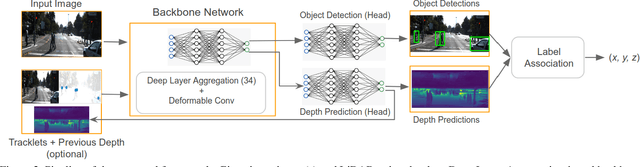
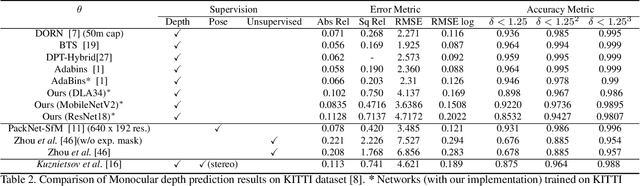
Determining accurate bird's eye view (BEV) positions of objects and tracks in a scene is vital for various perception tasks including object interactions mapping, scenario extraction etc., however, the level of supervision required to accomplish that is extremely challenging to procure. We propose a light-weight, weakly supervised method to estimate 3D position of objects by jointly learning to regress the 2D object detections and scene's depth prediction in a single feed-forward pass of a network. Our proposed method extends a center-point based single-shot object detector, and introduces a novel object representation where each object is modeled as a BEV point spatio-temporally, without the need of any 3D or BEV annotations for training and LiDAR data at query time. The approach leverages readily available 2D object supervision along with LiDAR point clouds (used only during training) to jointly train a single network, that learns to predict 2D object detection alongside the whole scene's depth, to spatio-temporally model object tracks as points in BEV. The proposed method is computationally over $\sim$10x efficient compared to recent SOTA approaches while achieving comparable accuracies on KITTI tracking benchmark.