 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic White-Box Testing of First-Order Logic Ontologies
Jun 26, 2018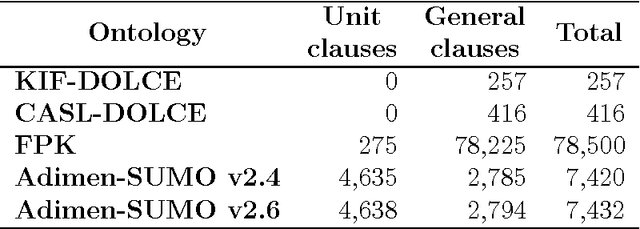
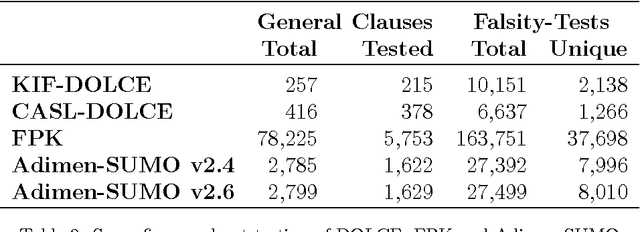

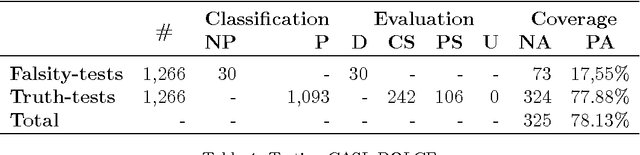
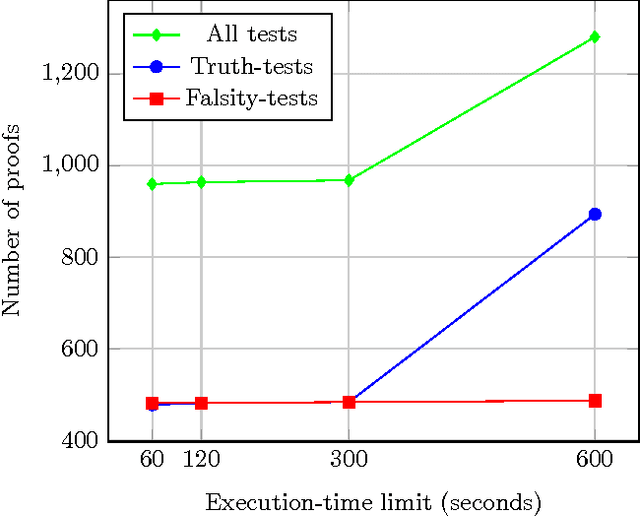
Formal ontologies are axiomatizations in a logic-based formalism. The development of formal ontologies, and their important role in the Semantic Web area, is generating considerable research on the use of automated reasoning techniques and tools that help in ontology engineering. One of the main aims is to refine and to improve axiomatizations for enabling automated reasoning tools to efficiently infer reliable information. Defects in the axiomatization can not only cause wrong inferences, but can also hinder the inference of expected information, either by increasing the computational cost of, or even preventing, the inference. In this paper, we introduce a novel, fully automatic white-box testing framework for first-order logic ontologies. Our methodology is based on the detection of inference-based redundancies in the given axiomatization. The application of the proposed testing method is fully automatic since a) the automated generation of tests is guided only by the syntax of axioms and b) the evaluation of tests is performed by automated theorem provers. Our proposal enables the detection of defects and serves to certify the grade of suitability --for reasoning purposes-- of every axiom. We formally define the set of tests that are generated from any axiom and prove that every test is logically related to redundancies in the axiom from which the test has been generated. We have implemented our method and used this implementation to automatically detect several non-trivial defects that were hidden in various first-order logic ontologies. Throughout the paper we provide illustrative examples of these defects, explain how they were found, and how each proof --given by an automated theorem-prover-- provides useful hints on the nature of each defect. Additionally, by correcting all the detected defects, we have obtained an improved version of one of the tested ontologies: Adimen-SUMO.
Black-box Testing of First-Order Logic Ontologies Using WordNet
Mar 23, 2018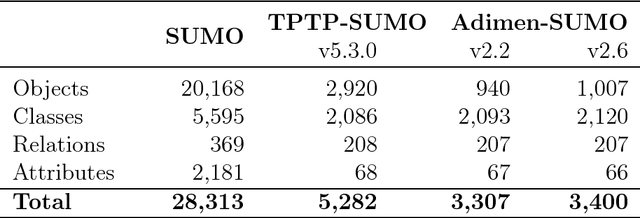

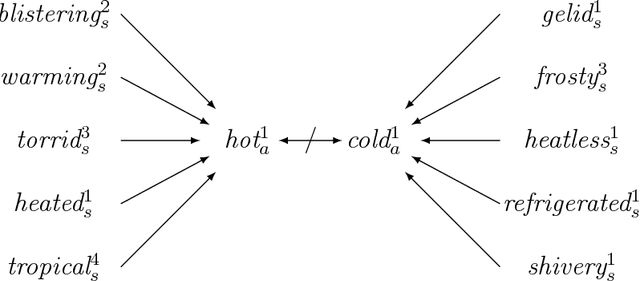
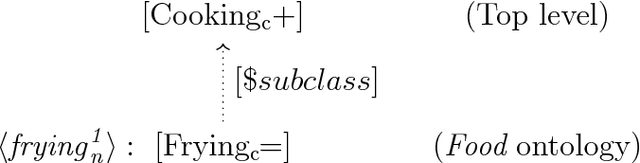
Artificial Intelligence aims to provide computer programs with commonsense knowledge to reason about our world. This paper offers a new practical approach towards automated commonsense reasoning with first-order logic (FOL) ontologies. We propose a new black-box testing methodology of FOL SUMO-based ontologies by exploiting WordNet and its mapping into SUMO. Our proposal includes a method for the (semi-)automatic creation of a very large benchmark of competency questions and a procedure for its automated evaluation by using automated theorem provers (ATPs). Applying different quality criteria, our testing proposal enables a successful evaluation of a) the competency of several translations of SUMO into FOL and b) the performance of various automated ATPs. Finally, we also provide a fine-grained and complete analysis of the commonsense reasoning competency of current FOL SUMO-based ontologies.
Evaluating the Competency of a First-Order Ontology
Oct 16, 2015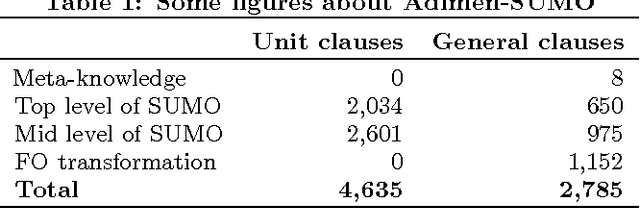
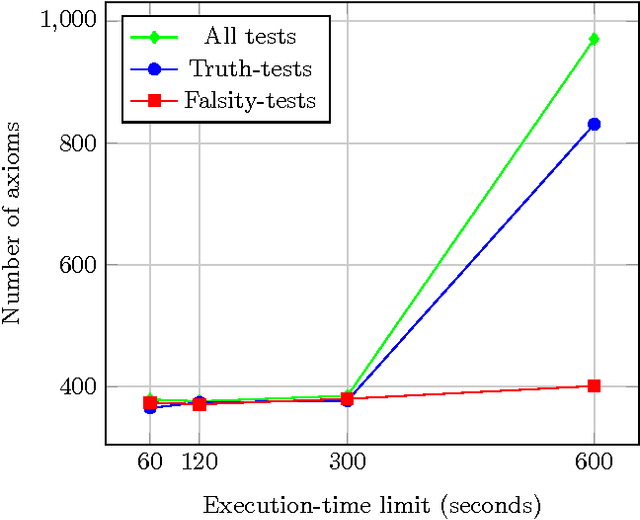
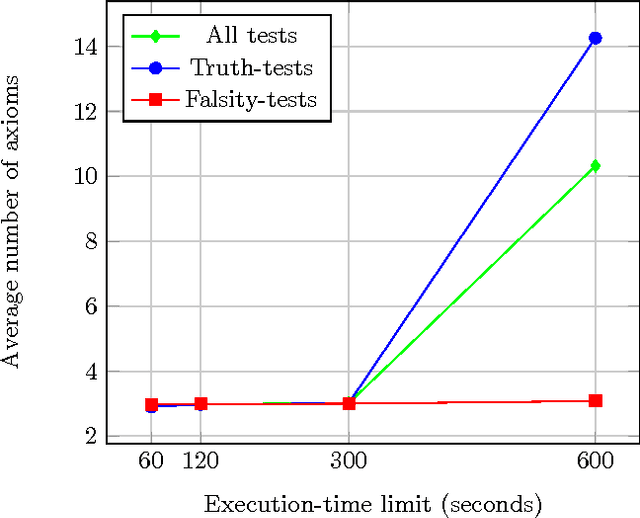
We report on the results of evaluating the competency of a first-order ontology for its use with automated theorem provers (ATPs). The evaluation follows the adaptation of the methodology based on competency questions (CQs) [Gr\"uninger&Fox,1995] to the framework of first-order logic, which is presented in [\'Alvez&Lucio&Rigau,2015], and is applied to Adimen-SUMO [\'Alvez&Lucio&Rigau,2015]. The set of CQs used for this evaluation has been automatically generated from a small set of semantic patterns and the mapping of WordNet to SUMO. Analysing the results, we can conclude that it is feasible to use ATPs for working with Adimen-SUMO v2.4, enabling the resolution of goals by means of performing non-trivial inferences.
* 4 pages, 4 figures
Improving the Competency of First-Order Ontologies
Oct 16, 2015
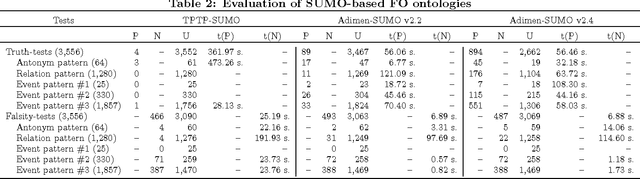
We introduce a new framework to evaluate and improve first-order (FO) ontologies using automated theorem provers (ATPs) on the basis of competency questions (CQs). Our framework includes both the adaptation of a methodology for evaluating ontologies to the framework of first-order logic and a new set of non-trivial CQs designed to evaluate FO versions of SUMO, which significantly extends the very small set of CQs proposed in the literature. Most of these new CQs have been automatically generated from a small set of patterns and the mapping of WordNet to SUMO. Applying our framework, we demonstrate that Adimen-SUMO v2.2 outperforms TPTP-SUMO. In addition, using the feedback provided by ATPs we have set an improved version of Adimen-SUMO (v2.4). This new version outperforms the previous ones in terms of competency. For instance, "Humans can reason" is automatically inferred from Adimen-SUMO v2.4, while it is neither deducible from TPTP-SUMO nor Adimen-SUMO v2.2.
* 8 pages, 2 tables