 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTruth Validation with Evidence
Feb 15, 2018



In the modern era, abundant information is easily accessible from various sources, however only a few of these sources are reliable as they mostly contain unverified contents. We develop a system to validate the truthfulness of a given statement together with underlying evidence. The proposed system provides supporting evidence when the statement is tagged as false. Our work relies on an inference method on a knowledge graph (KG) to identify the truthfulness of statements. In order to extract the evidence of falseness, the proposed algorithm takes into account combined knowledge from KG and ontologies. The system shows very good results as it provides valid and concise evidence. The quality of KG plays a role in the performance of the inference method which explicitly affects the performance of our evidence-extracting algorithm.
A Semi-supervised learning approach to enhance health care Community-based Question Answering: A case study in alcoholism
Jul 04, 2016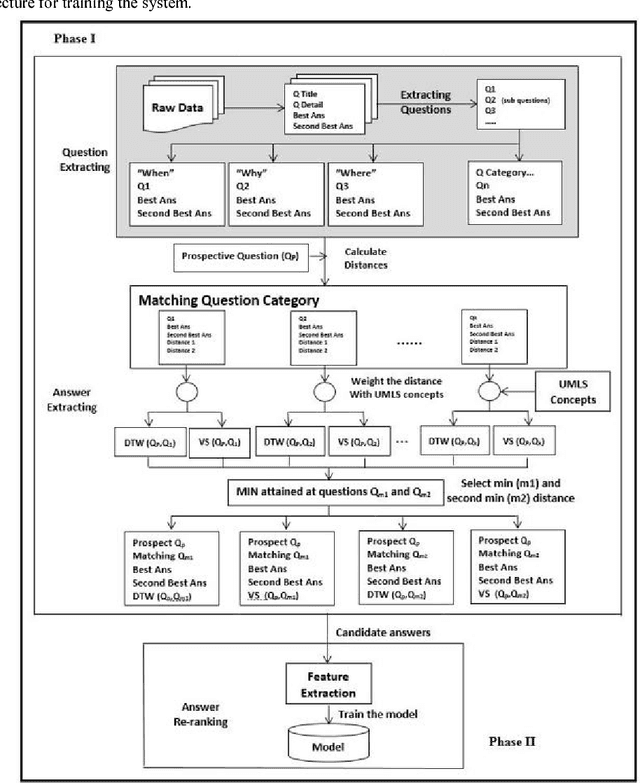

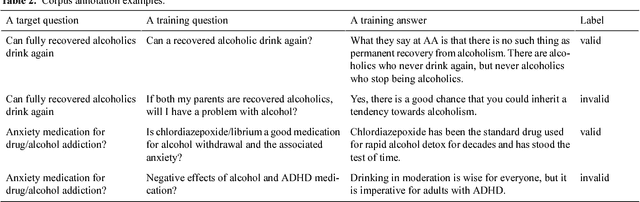
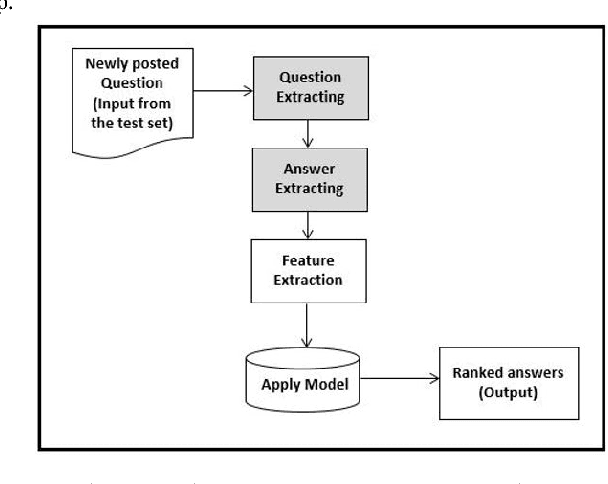
Community-based Question Answering (CQA) sites play an important role in addressing health information needs. However, a significant number of posted questions remain unanswered. Automatically answering the posted questions can provide a useful source of information for online health communities. In this study, we developed an algorithm to automatically answer health-related questions based on past questions and answers (QA). We also aimed to understand information embedded within online health content that are good features in identifying valid answers. Our proposed algorithm uses information retrieval techniques to identify candidate answers from resolved QA. In order to rank these candidates, we implemented a semi-supervised leaning algorithm that extracts the best answer to a question. We assessed this approach on a curated corpus from Yahoo! Answers and compared against a rule-based string similarity baseline. On our dataset, the semi-supervised learning algorithm has an accuracy of 86.2%. UMLS-based (health-related) features used in the model enhance the algorithm's performance by proximately 8 %. A reasonably high rate of accuracy is obtained given that the data is considerably noisy. Important features distinguishing a valid answer from an invalid answer include text length, number of stop words contained in a test question, a distance between the test question and other questions in the corpus as well as a number of overlapping health-related terms between questions. Overall, our automated QA system based on historical QA pairs is shown to be effective according to the data set in this case study. It is developed for general use in the health care domain which can also be applied to other CQA sites.
Predicting litigation likelihood and time to litigation for patents
Mar 23, 2016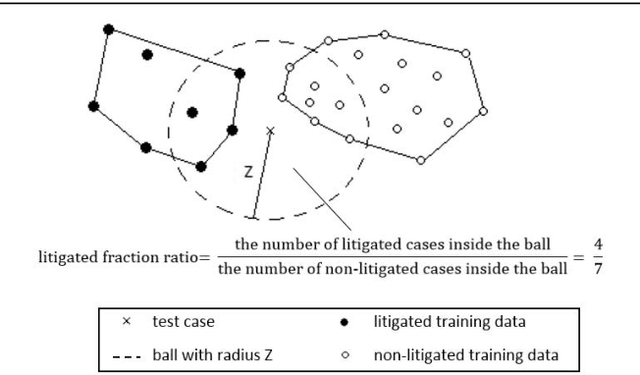
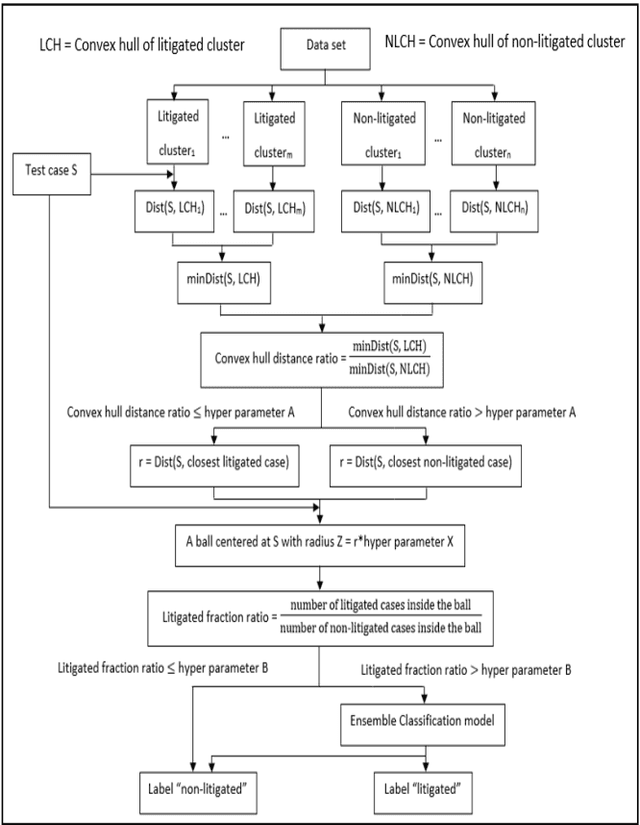
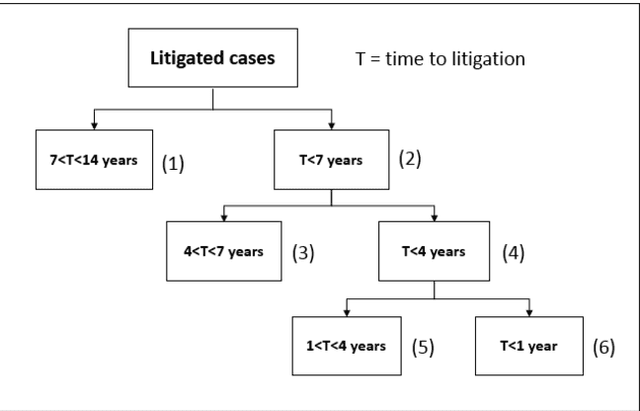
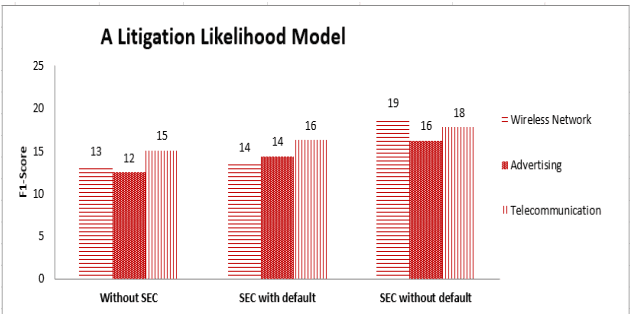
Patent lawsuits are costly and time-consuming. An ability to forecast a patent litigation and time to litigation allows companies to better allocate budget and time in managing their patent portfolios. We develop predictive models for estimating the likelihood of litigation for patents and the expected time to litigation based on both textual and non-textual features. Our work focuses on improving the state-of-the-art by relying on a different set of features and employing more sophisticated algorithms with more realistic data. The rate of patent litigations is very low, which consequently makes the problem difficult. The initial model for predicting the likelihood is further modified to capture a time-to-litigation perspective.