 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"So, Tell Me About Your Policy...": Distillation of interpretable policies from Deep Reinforcement Learning agents
Jul 10, 2025Recent advances in Reinforcement Learning (RL) largely benefit from the inclusion of Deep Neural Networks, boosting the number of novel approaches proposed in the field of Deep Reinforcement Learning (DRL). These techniques demonstrate the ability to tackle complex games such as Atari, Go, and other real-world applications, including financial trading. Nevertheless, a significant challenge emerges from the lack of interpretability, particularly when attempting to comprehend the underlying patterns learned, the relative importance of the state features, and how they are integrated to generate the policy's output. For this reason, in mission-critical and real-world settings, it is often preferred to deploy a simpler and more interpretable algorithm, although at the cost of performance. In this paper, we propose a novel algorithm, supported by theoretical guarantees, that can extract an interpretable policy (e.g., a linear policy) without disregarding the peculiarities of expert behavior. This result is obtained by considering the advantage function, which includes information about why an action is superior to the others. In contrast to previous works, our approach enables the training of an interpretable policy using previously collected experience. The proposed algorithm is empirically evaluated on classic control environments and on a financial trading scenario, demonstrating its ability to extract meaningful information from complex expert policies.
Interpetable Target-Feature Aggregation for Multi-Task Learning based on Bias-Variance Analysis
Jun 12, 2024
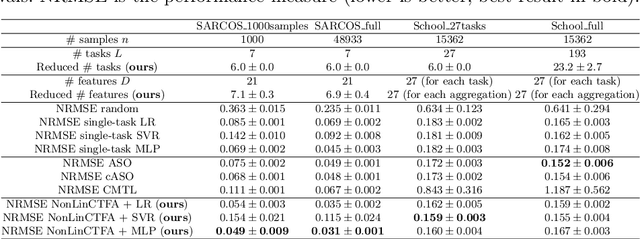
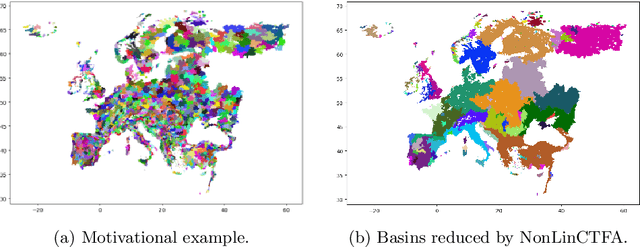
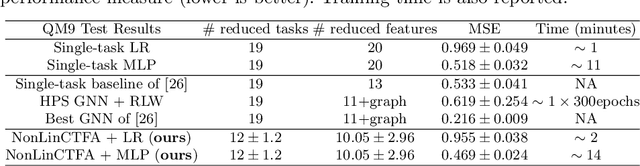
Multi-task learning (MTL) is a powerful machine learning paradigm designed to leverage shared knowledge across tasks to improve generalization and performance. Previous works have proposed approaches to MTL that can be divided into feature learning, focused on the identification of a common feature representation, and task clustering, where similar tasks are grouped together. In this paper, we propose an MTL approach at the intersection between task clustering and feature transformation based on a two-phase iterative aggregation of targets and features. First, we propose a bias-variance analysis for regression models with additive Gaussian noise, where we provide a general expression of the asymptotic bias and variance of a task, considering a linear regression trained on aggregated input features and an aggregated target. Then, we exploit this analysis to provide a two-phase MTL algorithm (NonLinCTFA). Firstly, this method partitions the tasks into clusters and aggregates each obtained group of targets with their mean. Then, for each aggregated task, it aggregates subsets of features with their mean in a dimensionality reduction fashion. In both phases, a key aspect is to preserve the interpretability of the reduced targets and features through the aggregation with the mean, which is further motivated by applications to Earth science. Finally, we validate the algorithms on synthetic data, showing the effect of different parameters and real-world datasets, exploring the validity of the proposed methodology on classical datasets, recent baselines, and Earth science applications.
Causal Feature Selection via Transfer Entropy
Oct 17, 2023



Machine learning algorithms are designed to capture complex relationships between features. In this context, the high dimensionality of data often results in poor model performance, with the risk of overfitting. Feature selection, the process of selecting a subset of relevant and non-redundant features, is, therefore, an essential step to mitigate these issues. However, classical feature selection approaches do not inspect the causal relationship between selected features and target, which can lead to misleading results in real-world applications. Causal discovery, instead, aims to identify causal relationships between features with observational data. In this paper, we propose a novel methodology at the intersection between feature selection and causal discovery, focusing on time series. We introduce a new causal feature selection approach that relies on the forward and backward feature selection procedures and leverages transfer entropy to estimate the causal flow of information from the features to the target in time series. Our approach enables the selection of features not only in terms of mere model performance but also captures the causal information flow. In this context, we provide theoretical guarantees on the regression and classification errors for both the exact and the finite-sample cases. Finally, we present numerical validations on synthetic and real-world regression problems, showing results competitive w.r.t. the considered baselines.
Nonlinear Feature Aggregation: Two Algorithms driven by Theory
Jun 19, 2023



Many real-world machine learning applications are characterized by a huge number of features, leading to computational and memory issues, as well as the risk of overfitting. Ideally, only relevant and non-redundant features should be considered to preserve the complete information of the original data and limit the dimensionality. Dimensionality reduction and feature selection are common preprocessing techniques addressing the challenge of efficiently dealing with high-dimensional data. Dimensionality reduction methods control the number of features in the dataset while preserving its structure and minimizing information loss. Feature selection aims to identify the most relevant features for a task, discarding the less informative ones. Previous works have proposed approaches that aggregate features depending on their correlation without discarding any of them and preserving their interpretability through aggregation with the mean. A limitation of methods based on correlation is the assumption of linearity in the relationship between features and target. In this paper, we relax such an assumption in two ways. First, we propose a bias-variance analysis for general models with additive Gaussian noise, leading to a dimensionality reduction algorithm (NonLinCFA) which aggregates non-linear transformations of features with a generic aggregation function. Then, we extend the approach assuming that a generalized linear model regulates the relationship between features and target. A deviance analysis leads to a second dimensionality reduction algorithm (GenLinCFA), applicable to a larger class of regression problems and classification settings. Finally, we test the algorithms on synthetic and real-world datasets, performing regression and classification tasks, showing competitive performances.
Interpretable Linear Dimensionality Reduction based on Bias-Variance Analysis
Mar 26, 2023



One of the central issues of several machine learning applications on real data is the choice of the input features. Ideally, the designer should select only the relevant, non-redundant features to preserve the complete information contained in the original dataset, with little collinearity among features and a smaller dimension. This procedure helps mitigate problems like overfitting and the curse of dimensionality, which arise when dealing with high-dimensional problems. On the other hand, it is not desirable to simply discard some features, since they may still contain information that can be exploited to improve results. Instead, dimensionality reduction techniques are designed to limit the number of features in a dataset by projecting them into a lower-dimensional space, possibly considering all the original features. However, the projected features resulting from the application of dimensionality reduction techniques are usually difficult to interpret. In this paper, we seek to design a principled dimensionality reduction approach that maintains the interpretability of the resulting features. Specifically, we propose a bias-variance analysis for linear models and we leverage these theoretical results to design an algorithm, Linear Correlated Features Aggregation (LinCFA), which aggregates groups of continuous features with their average if their correlation is "sufficiently large". In this way, all features are considered, the dimensionality is reduced and the interpretability is preserved. Finally, we provide numerical validations of the proposed algorithm both on synthetic datasets to confirm the theoretical results and on real datasets to show some promising applications.