 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Low Degree Hypergraphs
Feb 21, 2022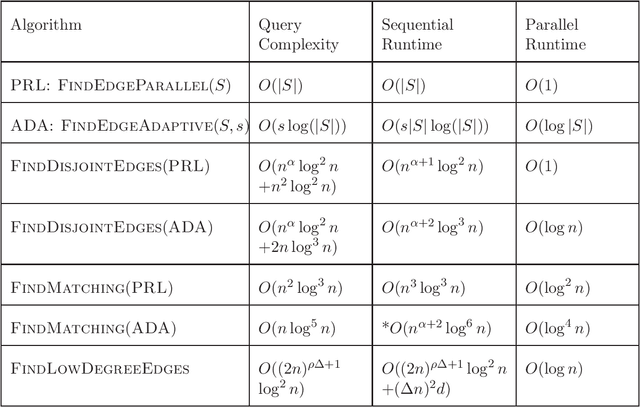
We study the problem of learning a hypergraph via edge detecting queries. In this problem, a learner queries subsets of vertices of a hidden hypergraph and observes whether these subsets contain an edge or not. In general, learning a hypergraph with $m$ edges of maximum size $d$ requires $\Omega((2m/d)^{d/2})$ queries. In this paper, we aim to identify families of hypergraphs that can be learned without suffering from a query complexity that grows exponentially in the size of the edges. We show that hypermatchings and low-degree near-uniform hypergraphs with $n$ vertices are learnable with poly$(n)$ queries. For learning hypermatchings (hypergraphs of maximum degree $ 1$), we give an $O(\log^3 n)$-round algorithm with $O(n \log^5 n)$ queries. We complement this upper bound by showing that there are no algorithms with poly$(n)$ queries that learn hypermatchings in $o(\log \log n)$ adaptive rounds. For hypergraphs with maximum degree $\Delta$ and edge size ratio $\rho$, we give a non-adaptive algorithm with $O((2n)^{\rho \Delta+1}\log^2 n)$ queries. To the best of our knowledge, these are the first algorithms with poly$(n, m)$ query complexity for learning non-trivial families of hypergraphs that have a super-constant number of edges of super-constant size.