 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Compromise in Solution Quality: Speeding Up Belief-dependent Continuous POMDPs via Adaptive Multilevel Simplification
Oct 16, 2023Continuous POMDPs with general belief-dependent rewards are notoriously difficult to solve online. In this paper, we present a complete provable theory of adaptive multilevel simplification for the setting of a given externally constructed belief tree and MCTS that constructs the belief tree on the fly using an exploration technique. Our theory allows to accelerate POMDP planning with belief-dependent rewards without any sacrifice in the quality of the obtained solution. We rigorously prove each theoretical claim in the proposed unified theory. Using the general theoretical results, we present three algorithms to accelerate continuous POMDP online planning with belief-dependent rewards. Our two algorithms, SITH-BSP and LAZY-SITH-BSP, can be utilized on top of any method that constructs a belief tree externally. The third algorithm, SITH-PFT, is an anytime MCTS method that permits to plug-in any exploration technique. All our methods are guaranteed to return exactly the same optimal action as their unsimplified equivalents. We replace the costly computation of information-theoretic rewards with novel adaptive upper and lower bounds which we derive in this paper, and are of independent interest. We show that they are easy to calculate and can be tightened by the demand of our algorithms. Our approach is general; namely, any bounds that monotonically converge to the reward can be easily plugged-in to achieve significant speedup without any loss in performance. Our theory and algorithms support the challenging setting of continuous states, actions, and observations. The beliefs can be parametric or general and represented by weighted particles. We demonstrate in simulation a significant speedup in planning compared to baseline approaches with guaranteed identical performance.
Simplified Belief-Dependent Reward MCTS Planning with Guaranteed Tree Consistency
May 29, 2021
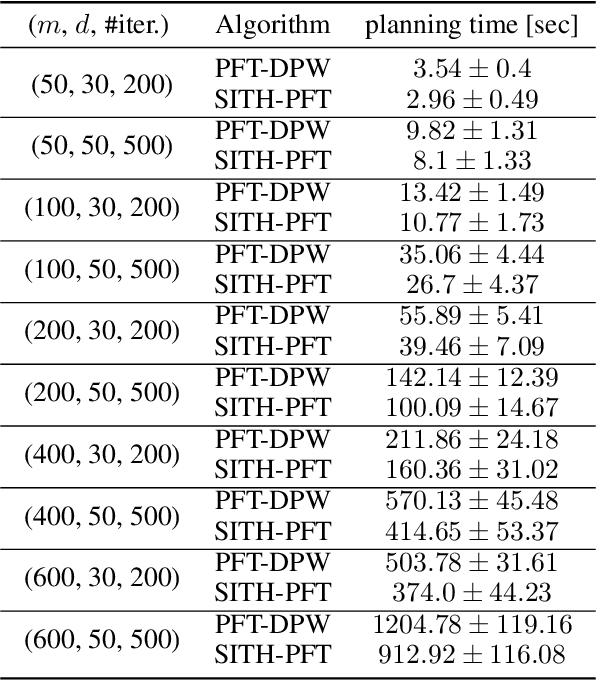
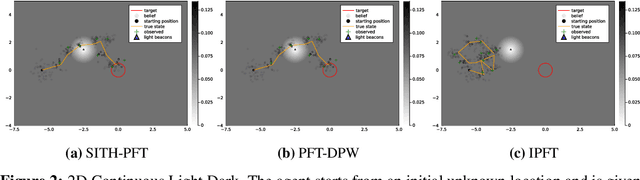
Partially Observable Markov Decision Processes (POMDPs) are notoriously hard to solve. Most advanced state-of-the-art online solvers leverage ideas of Monte Carlo Tree Search (MCTS). These solvers rapidly converge to the most promising branches of the belief tree, avoiding the suboptimal sections. Most of these algorithms are designed to utilize straightforward access to the state reward and assume the belief-dependent reward is nothing but expectation over the state reward. Thus, they are inapplicable to a more general and essential setting of belief-dependent rewards. One example of such reward is differential entropy approximated using a set of weighted particles of the belief. Such an information-theoretic reward introduces a significant computational burden. In this paper, we embed the paradigm of simplification into the MCTS algorithm. In particular, we present Simplified Information-Theoretic Particle Filter Tree (SITH-PFT), a novel variant to the MCTS algorithm that considers information-theoretic rewards but avoids the need to calculate them completely. We replace the costly calculation of information-theoretic rewards with adaptive upper and lower bounds. These bounds are easy to calculate and tightened only by the demand of our algorithm. Crucially, we guarantee precisely the same belief tree and solution that would be obtained by MCTS, which explicitly calculates the original information-theoretic rewards. Our approach is general; namely, any converging to the reward bounds can be easily plugged-in to achieve substantial speedup without any loss in performance.
Online POMDP Planning via Simplification
May 11, 2021


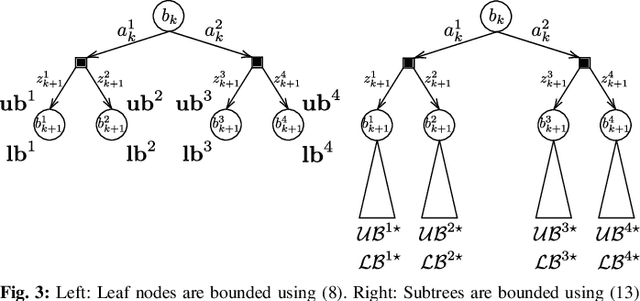
In this paper, we consider online planning in partially observable domains. Solving the corresponding POMDP problem is a very challenging task, particularly in an online setting. Our key contribution is a novel algorithmic approach, Simplified Information Theoretic Belief Space Planning (SITH-BSP), which aims to speed-up POMDP planning considering belief-dependent rewards, without compromising on the solution's accuracy. We do so by mathematically relating the simplified elements of the problem to the corresponding counterparts of the original problem. Specifically, we focus on belief simplification and use it to formulate bounds on the corresponding original belief-dependent rewards. These bounds in turn are used to perform branch pruning over the belief tree, in the process of calculating the optimal policy. We further introduce the notion of adaptive simplification, while re-using calculations between different simplification levels and exploit it to prune, at each level in the belief tree, all branches but one. Therefore, our approach is guaranteed to find the optimal solution of the original problem but with substantial speedup. As a second key contribution, we derive novel analytical bounds for differential entropy, considering a sampling-based belief representation, which we believe are of interest on their own. We validate our approach in simulation using these bounds and where simplification corresponds to reducing the number of samples, exhibiting a significant computational speedup while yielding the optimal solution.