 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuthorship Verification based on the Likelihood Ratio of Grammar Models
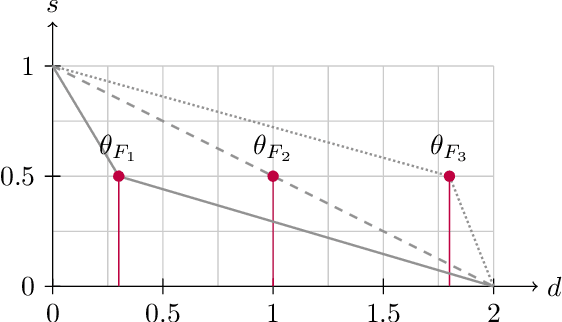
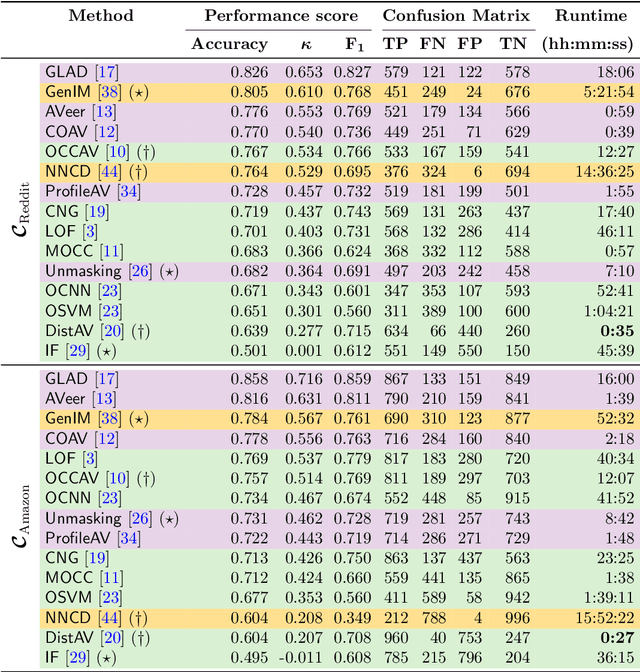
Mar 13, 2024Authorship Verification (AV) is the process of analyzing a set of documents to determine whether they were written by a specific author. This problem often arises in forensic scenarios, e.g., in cases where the documents in question constitute evidence for a crime. Existing state-of-the-art AV methods use computational solutions that are not supported by a plausible scientific explanation for their functioning and that are often difficult for analysts to interpret. To address this, we propose a method relying on calculating a quantity we call $\lambda_G$ (LambdaG): the ratio between the likelihood of a document given a model of the Grammar for the candidate author and the likelihood of the same document given a model of the Grammar for a reference population. These Grammar Models are estimated using $n$-gram language models that are trained solely on grammatical features. Despite not needing large amounts of data for training, LambdaG still outperforms other established AV methods with higher computational complexity, including a fine-tuned Siamese Transformer network. Our empirical evaluation based on four baseline methods applied to twelve datasets shows that LambdaG leads to better results in terms of both accuracy and AUC in eleven cases and in all twelve cases if considering only topic-agnostic methods. The algorithm is also highly robust to important variations in the genre of the reference population in many cross-genre comparisons. In addition to these properties, we demonstrate how LambdaG is easier to interpret than the current state-of-the-art. We argue that the advantage of LambdaG over other methods is due to fact that it is compatible with Cognitive Linguistic theories of language processing.
A Step Towards Interpretable Authorship Verification
Jul 07, 2020

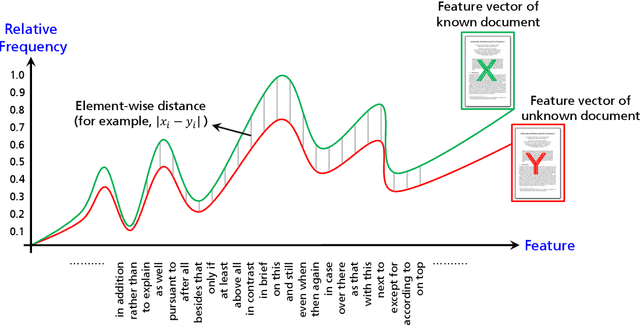
A central problem that has been researched for many years in the field of digital text forensics is the question whether two documents were written by the same author. Authorship verification (AV) is a research branch in this field that deals with this question. Over the years, research activities in the context of AV have steadily increased, which has led to a variety of approaches trying to solve this problem. Many of these approaches, however, make use of features that are related to or influenced by the topic of the documents. Therefore, it may accidentally happen that their verification results are based not on the writing style (the actual focus of AV), but on the topic of the documents. To address this problem, we propose an alternative AV approach that considers only topic-agnostic features in its classification decision. In addition, we present a post-hoc interpretation method that allows to understand which particular features have contributed to the prediction of the proposed AV method. To evaluate the performance of our AV method, we compared it with ten competing baselines (including the current state of the art) on four challenging data sets. The results show that our approach outperforms all baselines in two cases (with a maximum accuracy of 84%), while in the other two cases it performs as well as the strongest baseline.
An Improved Topic Masking Technique for Authorship Analysis
May 02, 2020


Authorship verification (AV) is an important sub-area of digital text forensics and has been researched for more than two decades. The fundamental question addressed by AV is whether two documents were written by the same person. A serious problem that has received little attention in the literature so far is the question if AV methods actually focus on the writing style during classification, or whether they are unintentionally distorted by the topic of the documents. To counteract this problem, we propose an effective technique called POSNoise, which aims to mask topic-related content in documents. In this way, AV methods are forced to focus on those text units that are more related to the author's writing style. Based on a comprehensive evaluation with eight existing AV methods applied to eight corpora, we demonstrate that POSNoise is able to outperform a well-known topic masking approach in 51 out of 64 cases with up to 12.5% improvement in terms of accuracy. Furthermore, we show that for corpora preprocessed with POSNoise, the AV methods examined often achieve higher accuracies (improvement of up to 20.6%) compared to the original corpora.
Assessing the Applicability of Authorship Verification Methods
Jun 24, 2019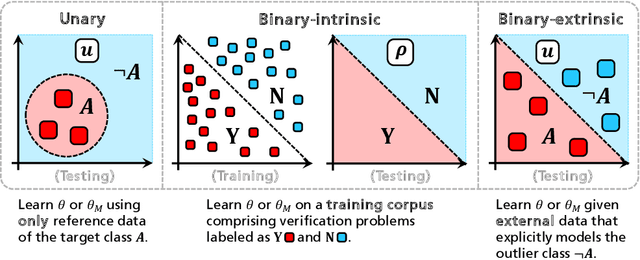
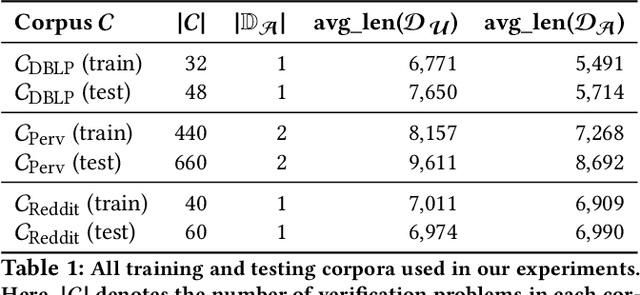
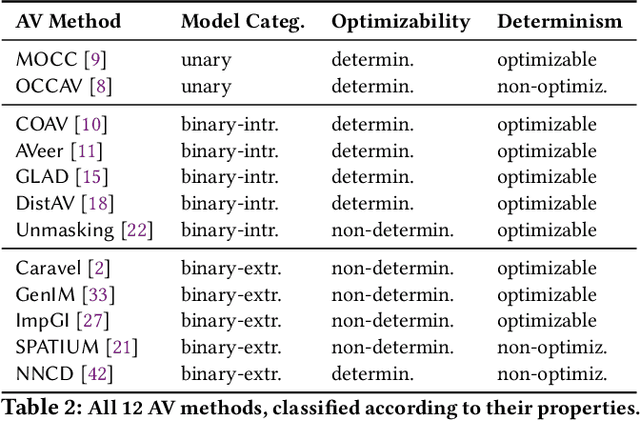
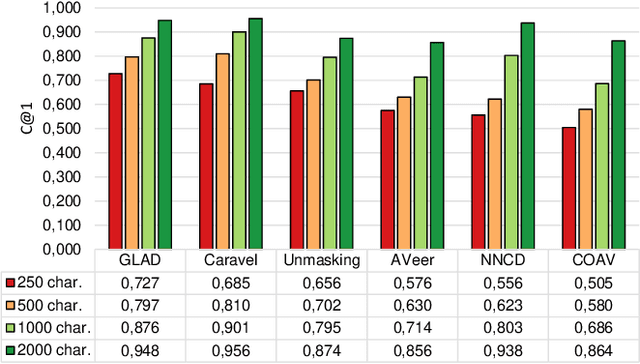
Authorship verification (AV) is a research subject in the field of digital text forensics that concerns itself with the question, whether two documents have been written by the same person. During the past two decades, an increasing number of proposed AV approaches can be observed. However, a closer look at the respective studies reveals that the underlying characteristics of these methods are rarely addressed, which raises doubts regarding their applicability in real forensic settings. The objective of this paper is to fill this gap by proposing clear criteria and properties that aim to improve the characterization of existing and future AV approaches. Based on these properties, we conduct three experiments using 12 existing AV approaches, including the current state of the art. The examined methods were trained, optimized and evaluated on three self-compiled corpora, where each corpus focuses on a different aspect of applicability. Our results indicate that part of the methods are able to cope with very challenging verification cases such as 250 characters long informal chat conversations (72.7% accuracy) or cases in which two scientific documents were written at different times with an average difference of 15.6 years (> 75% accuracy). However, we also identified that all involved methods are prone to cross-topic verification cases.
Unary and Binary Classification Approaches and their Implications for Authorship Verification
Dec 31, 2018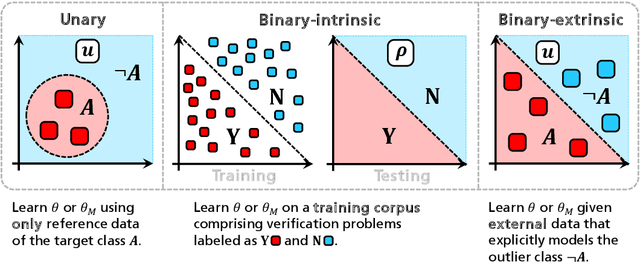
Retrieving indexed documents, not by their topical content but their writing style opens the door for a number of applications in information retrieval (IR). One application is to retrieve textual content of a certain author X, where the queried IR system is provided beforehand with a set of reference texts of X. Authorship verification (AV), which is a research subject in the field of digital text forensics, is suitable for this purpose. The task of AV is to determine if two documents (i.e. an indexed and a reference document) have been written by the same author X. Even though AV represents a unary classification problem, a number of existing approaches consider it as a binary classification task. However, the underlying classification model of an AV method has a number of serious implications regarding its prerequisites, evaluability, and applicability. In our comprehensive literature review, we observed several misunderstandings regarding the differentiation of unary and binary AV approaches that require consideration. The objective of this paper is, therefore, to clarify these by proposing clear criteria and new properties that aim to improve the characterization of existing and future AV approaches. Given both, we investigate the applicability of eleven existing unary and binary AV methods as well as four generic unary classification algorithms on two self-compiled corpora. Furthermore, we highlight an important issue concerning the evaluation of AV methods based on fixed decision criterions, which has not been paid attention in previous AV studies.