 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen Set Classification of GAN-based Image Manipulations via a ViT-based Hybrid Architecture
Apr 11, 2023



Classification of AI-manipulated content is receiving great attention, for distinguishing different types of manipulations. Most of the methods developed so far fail in the open-set scenario, that is when the algorithm used for the manipulation is not represented by the training set. In this paper, we focus on the classification of synthetic face generation and manipulation in open-set scenarios, and propose a method for classification with a rejection option. The proposed method combines the use of Vision Transformers (ViT) with a hybrid approach for simultaneous classification and localization. Feature map correlation is exploited by the ViT module, while a localization branch is employed as an attention mechanism to force the model to learn per-class discriminative features associated with the forgery when the manipulation is performed locally in the image. Rejection is performed by considering several strategies and analyzing the model output layers. The effectiveness of the proposed method is assessed for the task of classification of facial attribute editing and GAN attribution.
Which country is this picture from? New data and methods for DNN-based country recognition
Sep 02, 2022



Predicting the country where a picture has been taken from has many potential applications, like detection of false claims, impostors identification, prevention of disinformation campaigns, identification of fake news and so on. Previous works have focused mostly on the estimation of the geo-coordinates where a picture has been taken. Yet, recognizing the country where an image has been taken could potentially be more important, from a semantic and forensic point of view, than identifying its spatial coordinates. So far only a few works have addressed this task, mostly by relying on images containing characteristic landmarks, like iconic monuments. In the above framework, this paper provides two main contributions. First, we introduce a new dataset, the VIPPGeo dataset, containing almost 4 million images, that can be used to train DL models for country classification. The dataset contains only urban images given the relevance of this kind of image for country recognition, and it has been built by paying attention to removing non-significant images, like images portraying faces or specific, non-relevant objects, like airplanes or ships. Secondly, we used the dataset to train a deep learning architecture casting the country recognition problem as a classification problem. The experiments, we performed, show that our network provides significantly better results than current state of the art. In particular, we found that asking the network to directly identify the country provides better results than estimating the geo-coordinates first and then using them to trace back to the country where the picture was taken.
An Architecture for the detection of GAN-generated Flood Images with Localization Capabilities
May 14, 2022
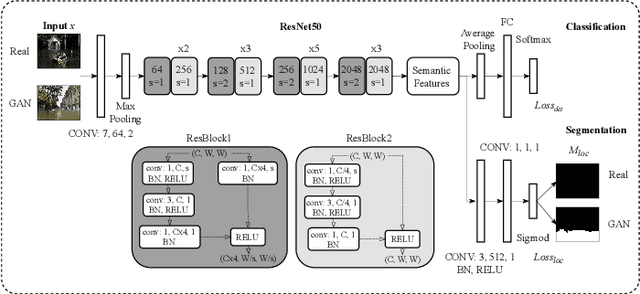
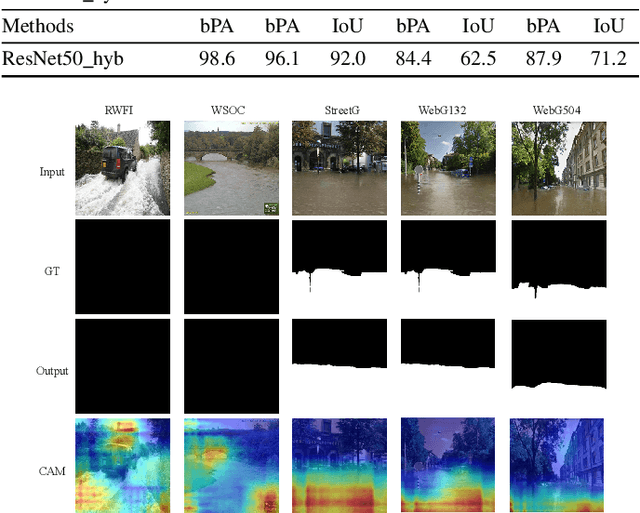
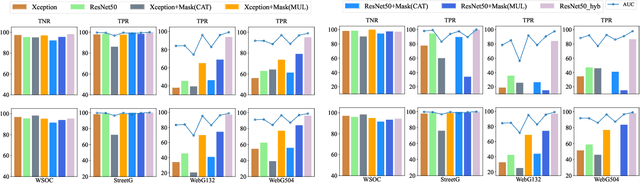
In this paper, we address a new image forensics task, namely the detection of fake flood images generated by ClimateGAN architecture. We do so by proposing a hybrid deep learning architecture including both a detection and a localization branch, the latter being devoted to the identification of the image regions manipulated by ClimateGAN. Even if our goal is the detection of fake flood images, in fact, we found that adding a localization branch helps the network to focus on the most relevant image regions with significant improvements in terms of generalization capabilities and robustness against image processing operations. The good performance of the proposed architecture is validated on two datasets of pristine flood images downloaded from the internet and three datasets of fake flood images generated by ClimateGAN starting from a large set of diverse street images.
Detection of GAN-synthesized street videos
Sep 17, 2021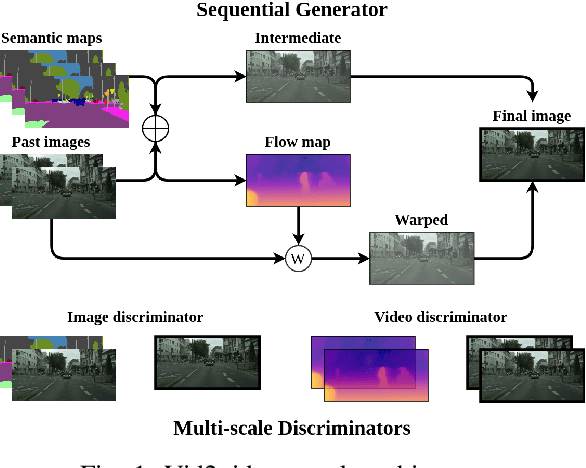

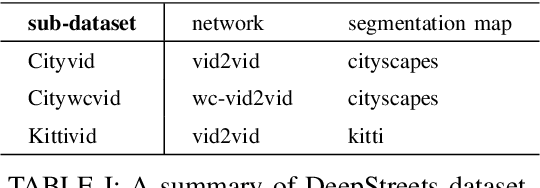
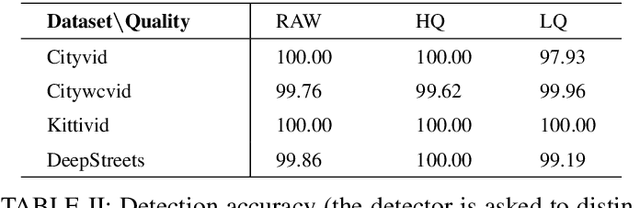
Research on the detection of AI-generated videos has focused almost exclusively on face videos, usually referred to as deepfakes. Manipulations like face swapping, face reenactment and expression manipulation have been the subject of an intense research with the development of a number of efficient tools to distinguish artificial videos from genuine ones. Much less attention has been paid to the detection of artificial non-facial videos. Yet, new tools for the generation of such kind of videos are being developed at a fast pace and will soon reach the quality level of deepfake videos. The goal of this paper is to investigate the detectability of a new kind of AI-generated videos framing driving street sequences (here referred to as DeepStreets videos), which, by their nature, can not be analysed with the same tools used for facial deepfakes. Specifically, we present a simple frame-based detector, achieving very good performance on state-of-the-art DeepStreets videos generated by the Vid2vid architecture. Noticeably, the detector retains very good performance on compressed videos, even when the compression level used during training does not match that used for the test videos.