 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Offline-Online Reinforcement Learning for Sensorless, High-Precision Force Regulation in Surgical Robotic Grasping
Feb 27, 2026Precise grasp force regulation in tendon-driven surgical instruments is fundamentally limited by nonlinear coupling between motor dynamics, transmission compliance, friction, and distal mechanics. Existing solutions typically rely on distal force sensing or analytical compensation, increasing hardware complexity or degrading performance under dynamic motion. We present a sensorless control framework that combines physics-consistent modeling and hybrid reinforcement learning to achieve high-precision distal force regulation in a proximally actuated surgical end-effector. We develop a first-principles digital twin of the da Vinci Xi grasping mechanism that captures coupled electrical, transmission, and jaw dynamics within a unified differential-algebraic formulation. To safely learn control policies in this stiff and highly nonlinear system, we introduce a three-stage pipeline:(i)a receding-horizon CMA-ES oracle that generates dynamically feasible expert trajectories,(ii)fully offline policy learning via Implicit Q-Learning to ensure stable initialization without unsafe exploration, and (iii)online refinement using TD3 for adaptation to on-policy dynamics. The resulting policy directly maps proximal measurements to motor voltages and requires no distal sensing. In simulation, the controller maintains grasp force within 1% of the desired reference during multi-harmonic jaw motion. Hardware experiments demonstrate average force errors below 4% across diverse trajectories, validating sim-to-real transfer. The learned policy contains approximately 71k param and executes at kH rates, enabling real-time deployment. These results demonstrate that high-fidelity modeling combined with structured offline-online RL can recover precise distal force behavior without additional sensing, offering a scalable and mechanically compatible solution for surgical robotic manipulation.
Multimodal Optimal Transport for Unsupervised Temporal Segmentation in Surgical Robotics
Feb 27, 2026Recognizing surgical phases and steps from video is a fundamental problem in computer-assisted interventions. Recent approaches increasingly rely on large-scale pre-training on thousands of labeled surgical videos, followed by zero-shot transfer to specific procedures. While effective, this strategy incurs substantial computational and data collection costs. In this work, we question whether such heavy pre-training is truly necessary. We propose Text-Augmented Action Segmentation Optimal Transport (TASOT), an unsupervised method for surgical phase and step recognition that extends Action Segmentation Optimal Transport (ASOT) by incorporating textual information generated directly from the videos. TASOT formulates temporal action segmentation as a multimodal optimal transport problem, where the matching cost is defined as a weighted combination of visual and text-based costs. The visual term captures frame-level appearance similarity, while the text term provides complementary semantic cues, and both are jointly regularized through a temporally consistent unbalanced Gromov-Wasserstein formulation. This design enables effective alignment between video frames and surgical actions without surgical-specific pretraining or external web-scale supervision. We evaluate TASOT on multiple benchmark surgical datasets and observe consistent and substantial improvements over existing zero-shot methods, including StrasBypass70 (+23.7), BernBypass70 (+4.5), Cholec80 (+16.5), and AutoLaparo (+19.6). These results demonstrate that fine-grained surgical understanding can be achieved by exploiting information already present in standard visual and textual representations, without resorting to increasingly complex pre-training pipelines. The code will be available at https://github.com/omar8ahmed9/TASOT.
An End-to-End OCR Framework for Robust Arabic-Handwriting Recognition using a Novel Transformers-based Model and an Innovative 270 Million-Words Multi-Font Corpus of Classical Arabic with Diacritics
Aug 26, 2022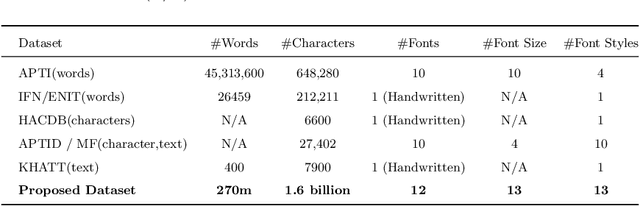


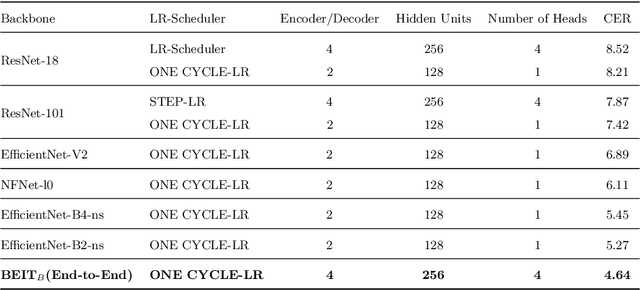
This research is the second phase in a series of investigations on developing an Optical Character Recognition (OCR) of Arabic historical documents and examining how different modeling procedures interact with the problem. The first research studied the effect of Transformers on our custom-built Arabic dataset. One of the downsides of the first research was the size of the training data, a mere 15000 images from our 30 million images, due to lack of resources. Also, we add an image enhancement layer, time and space optimization, and Post-Correction layer to aid the model in predicting the correct word for the correct context. Notably, we propose an end-to-end text recognition approach using Vision Transformers as an encoder, namely BEIT, and vanilla Transformer as a decoder, eliminating CNNs for feature extraction and reducing the model's complexity. The experiments show that our end-to-end model outperforms Convolutions Backbones. The model attained a CER of 4.46%.
Arabic Speech Emotion Recognition Employing Wav2vec2.0 and HuBERT Based on BAVED Dataset
Oct 09, 2021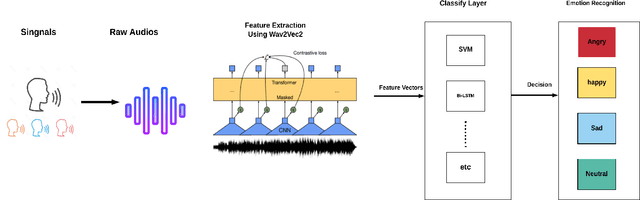

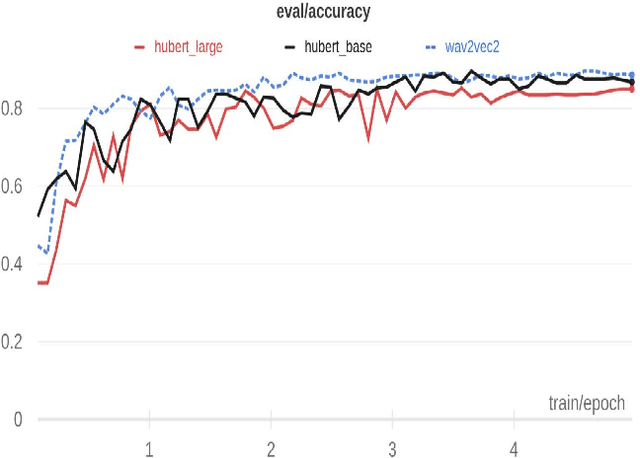

Recently, there have been tremendous research outcomes in the fields of speech recognition and natural language processing. This is due to the well-developed multi-layers deep learning paradigms such as wav2vec2.0, Wav2vecU, WavBERT, and HuBERT that provide better representation learning and high information capturing. Such paradigms run on hundreds of unlabeled data, then fine-tuned on a small dataset for specific tasks. This paper introduces a deep learning constructed emotional recognition model for Arabic speech dialogues. The developed model employs the state of the art audio representations include wav2vec2.0 and HuBERT. The experiment and performance results of our model overcome the previous known outcomes.
Autonomous Navigation in Dynamic Environments: Deep Learning-Based Approach
Feb 03, 2021



Mobile robotics is a research area that has witnessed incredible advances for the last decades. Robot navigation is an essential task for mobile robots. Many methods are proposed for allowing robots to navigate within different environments. This thesis studies different deep learning-based approaches, highlighting the advantages and disadvantages of each scheme. In fact, these approaches are promising that some of them can navigate the robot in unknown and dynamic environments. In this thesis, one of the deep learning methods based on convolutional neural network (CNN) is realized by software implementations. There are different preparation studies to complete this thesis such as introduction to Linux, robot operating system (ROS), C++, python, and GAZEBO simulator. Within this work, we modified the drone network (namely, DroNet) approach to be used in an indoor environment by using a ground robot in different cases. Indeed, the DroNet approach suffers from the absence of goal-oriented motion. Therefore, this thesis mainly focuses on tackling this problem via mapping using simultaneous localization and mapping (SLAM) and path planning techniques using Dijkstra. Afterward, the combination between the DroNet ground robot-based, mapping, and path planning leads to a goal-oriented motion, following the shortest path while avoiding the dynamic obstacle. Finally, we propose a low-cost approach, for indoor applications such as restaurants, museums, etc, on the base of using a monocular camera instead of a laser scanner.