 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn End-to-End OCR Framework for Robust Arabic-Handwriting Recognition using a Novel Transformers-based Model and an Innovative 270 Million-Words Multi-Font Corpus of Classical Arabic with Diacritics
Paper and Code
Aug 26, 2022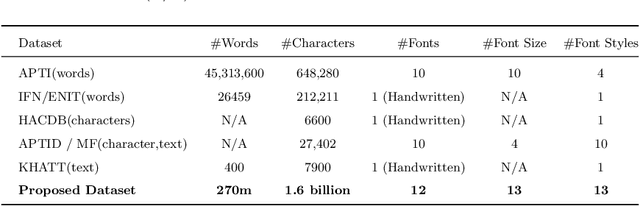


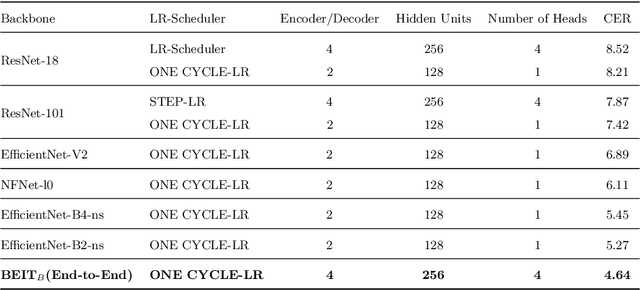
This research is the second phase in a series of investigations on developing an Optical Character Recognition (OCR) of Arabic historical documents and examining how different modeling procedures interact with the problem. The first research studied the effect of Transformers on our custom-built Arabic dataset. One of the downsides of the first research was the size of the training data, a mere 15000 images from our 30 million images, due to lack of resources. Also, we add an image enhancement layer, time and space optimization, and Post-Correction layer to aid the model in predicting the correct word for the correct context. Notably, we propose an end-to-end text recognition approach using Vision Transformers as an encoder, namely BEIT, and vanilla Transformer as a decoder, eliminating CNNs for feature extraction and reducing the model's complexity. The experiments show that our end-to-end model outperforms Convolutions Backbones. The model attained a CER of 4.46%.