Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArabic Speech Emotion Recognition Employing Wav2vec2.0 and HuBERT Based on BAVED Dataset
Paper and Code
Oct 09, 2021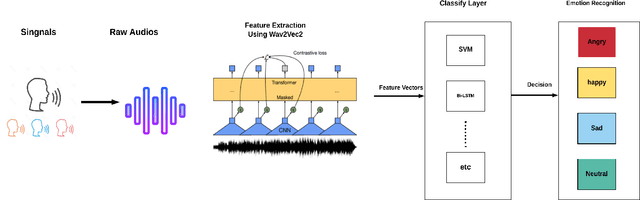

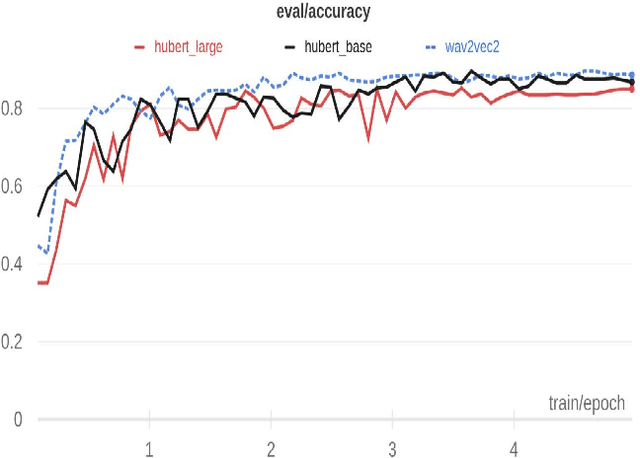

Recently, there have been tremendous research outcomes in the fields of speech recognition and natural language processing. This is due to the well-developed multi-layers deep learning paradigms such as wav2vec2.0, Wav2vecU, WavBERT, and HuBERT that provide better representation learning and high information capturing. Such paradigms run on hundreds of unlabeled data, then fine-tuned on a small dataset for specific tasks. This paper introduces a deep learning constructed emotional recognition model for Arabic speech dialogues. The developed model employs the state of the art audio representations include wav2vec2.0 and HuBERT. The experiment and performance results of our model overcome the previous known outcomes.
* 6 pages, 6 figures
View paper on