 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Forecasting at Scale
Oct 19, 2023Existing hierarchical forecasting techniques scale poorly when the number of time series increases. We propose to learn a coherent forecast for millions of time series with a single bottom-level forecast model by using a sparse loss function that directly optimizes the hierarchical product and/or temporal structure. The benefit of our sparse hierarchical loss function is that it provides practitioners a method of producing bottom-level forecasts that are coherent to any chosen cross-sectional or temporal hierarchy. In addition, removing the need for a post-processing step as required in traditional hierarchical forecasting techniques reduces the computational cost of the prediction phase in the forecasting pipeline. On the public M5 dataset, our sparse hierarchical loss function performs up to 10% (RMSE) better compared to the baseline loss function. We implement our sparse hierarchical loss function within an existing forecasting model at bol, a large European e-commerce platform, resulting in an improved forecasting performance of 2% at the product level. Finally, we found an increase in forecasting performance of about 5-10% when evaluating the forecasting performance across the cross-sectional hierarchies that we defined. These results demonstrate the usefulness of our sparse hierarchical loss applied to a production forecasting system at a major e-commerce platform.
Parameter Efficient Deep Probabilistic Forecasting
Dec 14, 2021



Probabilistic time series forecasting is crucial in many application domains such as retail, ecommerce, finance, or biology. With the increasing availability of large volumes of data, a number of neural architectures have been proposed for this problem. In particular, Transformer-based methods achieve state-of-the-art performance on real-world benchmarks. However, these methods require a large number of parameters to be learned, which imposes high memory requirements on the computational resources for training such models. To address this problem, we introduce a novel Bidirectional Temporal Convolutional Network (BiTCN), which requires an order of magnitude less parameters than a common Transformer-based approach. Our model combines two Temporal Convolutional Networks (TCNs): the first network encodes future covariates of the time series, whereas the second network encodes past observations and covariates. We jointly estimate the parameters of an output distribution via these two networks. Experiments on four real-world datasets show that our method performs on par with four state-of-the-art probabilistic forecasting methods, including a Transformer-based approach and WaveNet, on two point metrics (sMAPE, NRMSE) as well as on a set of range metrics (quantile loss percentiles) in the majority of cases. Secondly, we demonstrate that our method requires significantly less parameters than Transformer-based methods, which means the model can be trained faster with significantly lower memory requirements, which as a consequence reduces the infrastructure cost for deploying these models.
Probabilistic Gradient Boosting Machines for Large-Scale Probabilistic Regression
Jun 06, 2021


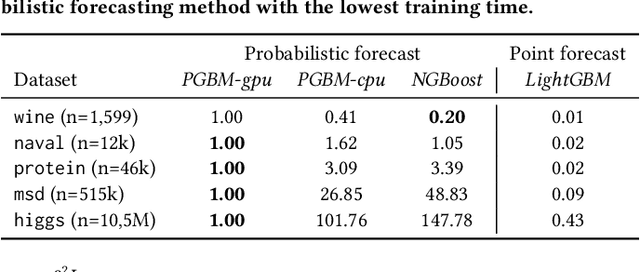
Gradient Boosting Machines (GBM) are hugely popular for solving tabular data problems. However, practitioners are not only interested in point predictions, but also in probabilistic predictions in order to quantify the uncertainty of the predictions. Creating such probabilistic predictions is difficult with existing GBM-based solutions: they either require training multiple models or they become too computationally expensive to be useful for large-scale settings. We propose Probabilistic Gradient Boosting Machines (PGBM), a method to create probabilistic predictions with a single ensemble of decision trees in a computationally efficient manner. PGBM approximates the leaf weights in a decision tree as a random variable, and approximates the mean and variance of each sample in a dataset via stochastic tree ensemble update equations. These learned moments allow us to subsequently sample from a specified distribution after training. We empirically demonstrate the advantages of PGBM compared to existing state-of-the-art methods: (i) PGBM enables probabilistic estimates without compromising on point performance in a single model, (ii) PGBM learns probabilistic estimates via a single model only (and without requiring multi-parameter boosting), and thereby offers a speedup of up to several orders of magnitude over existing state-of-the-art methods on large datasets, and (iii) PGBM achieves accurate probabilistic estimates in tasks with complex differentiable loss functions, such as hierarchical time series problems, where we observed up to 10% improvement in point forecasting performance and up to 300% improvement in probabilistic forecasting performance.
Reinforcement learning for port-Hamiltonian systems
Aug 22, 2013
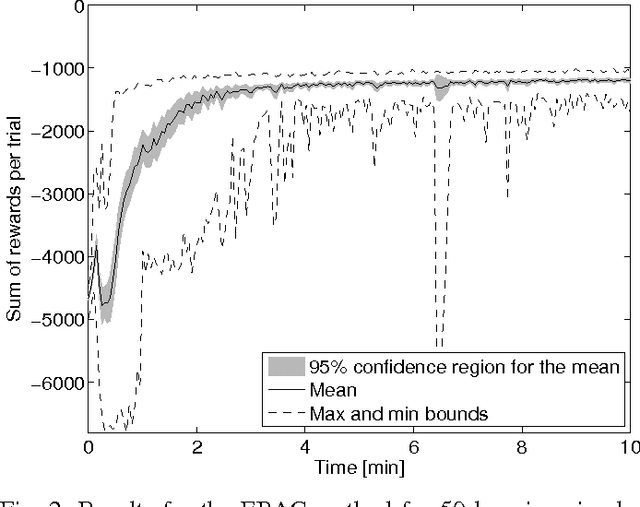

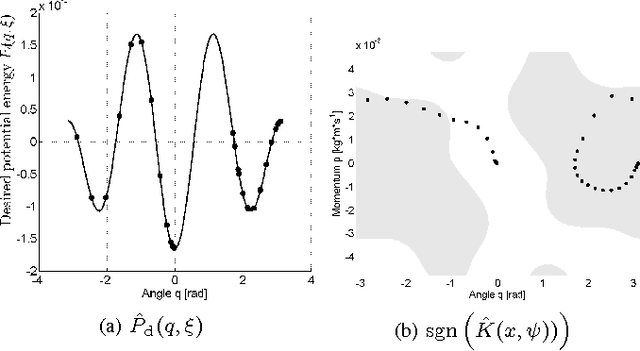
Passivity-based control (PBC) for port-Hamiltonian systems provides an intuitive way of achieving stabilization by rendering a system passive with respect to a desired storage function. However, in most instances the control law is obtained without any performance considerations and it has to be calculated by solving a complex partial differential equation (PDE). In order to address these issues we introduce a reinforcement learning approach into the energy-balancing passivity-based control (EB-PBC) method, which is a form of PBC in which the closed-loop energy is equal to the difference between the stored and supplied energies. We propose a technique to parameterize EB-PBC that preserves the systems's PDE matching conditions, does not require the specification of a global desired Hamiltonian, includes performance criteria, and is robust to extra non-linearities such as control input saturation. The parameters of the control law are found using actor-critic reinforcement learning, enabling learning near-optimal control policies satisfying a desired closed-loop energy landscape. The advantages are that near-optimal controllers can be generated using standard energy shaping techniques and that the solutions learned can be interpreted in terms of energy shaping and damping injection, which makes it possible to numerically assess stability using passivity theory. From the reinforcement learning perspective, our proposal allows for the class of port-Hamiltonian systems to be incorporated in the actor-critic framework, speeding up the learning thanks to the resulting parameterization of the policy. The method has been successfully applied to the pendulum swing-up problem in simulations and real-life experiments.