 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReservoir History Matching of the Norne field with generative exotic priors and a coupled Mixture of Experts -- Physics Informed Neural Operator Forward Model
Jun 02, 2024



We developed a novel reservoir characterization workflow that addresses reservoir history matching by coupling a physics-informed neural operator (PINO) forward model with a mixture of experts' approach, termed cluster classify regress (CCR). The inverse modelling is achieved via an adaptive Regularized Ensemble Kalman inversion (aREKI) method, ideal for rapid inverse uncertainty quantification during history matching. We parametrize unknown permeability and porosity fields for non-Gaussian posterior measures using a variational convolution autoencoder and a denoising diffusion implicit model (DDIM) exotic priors. The CCR works as a supervised model with the PINO surrogate to replicate nonlinear Peaceman well equations. The CCR's flexibility allows any independent machine-learning algorithm for each stage. The PINO reservoir surrogate's loss function is derived from supervised data loss and losses from the initial conditions and residual of the governing black oil PDE. The PINO-CCR surrogate outputs pressure, water, and gas saturations, along with oil, water, and gas production rates. The methodology was compared to a standard numerical black oil simulator for a waterflooding case on the Norne field, showing similar outputs. This PINO-CCR surrogate was then used in the aREKI history matching workflow, successfully recovering the unknown permeability, porosity and fault multiplier, with simulations up to 6000 times faster than conventional methods. Training the PINO-CCR surrogate on an NVIDIA H100 with 80G memory takes about 5 hours for 100 samples of the Norne field. This workflow is suitable for ensemble-based approaches, where posterior density sampling, given an expensive likelihood evaluation, is desirable for uncertainty quantification.
A Novel A.I Enhanced Reservoir Characterization with a Combined Mixture of Experts -- NVIDIA Modulus based Physics Informed Neural Operator Forward Model
Apr 20, 2024



We have developed an advanced workflow for reservoir characterization, effectively addressing the challenges of reservoir history matching through a novel approach. This method integrates a Physics Informed Neural Operator (PINO) as a forward model within a sophisticated Cluster Classify Regress (CCR) framework. The process is enhanced by an adaptive Regularized Ensemble Kalman Inversion (aREKI), optimized for rapid uncertainty quantification in reservoir history matching. This innovative workflow parameterizes unknown permeability and porosity fields, capturing non-Gaussian posterior measures with techniques such as a variational convolution autoencoder and the CCR. Serving as exotic priors and a supervised model, the CCR synergizes with the PINO surrogate to accurately simulate the nonlinear dynamics of Peaceman well equations. The CCR approach allows for flexibility in applying distinct machine learning algorithms across its stages. Updates to the PINO reservoir surrogate are driven by a loss function derived from supervised data, initial conditions, and residuals of governing black oil PDEs. Our integrated model, termed PINO-Res-Sim, outputs crucial parameters including pressures, saturations, and production rates for oil, water, and gas. Validated against traditional simulators through controlled experiments on synthetic reservoirs and the Norne field, the methodology showed remarkable accuracy. Additionally, the PINO-Res-Sim in the aREKI workflow efficiently recovered unknown fields with a computational speedup of 100 to 6000 times faster than conventional methods. The learning phase for PINO-Res-Sim, conducted on an NVIDIA H100, was impressively efficient, compatible with ensemble-based methods for complex computational tasks.
MLReal: Bridging the gap between training on synthetic data and real data applications in machine learning
Sep 11, 2021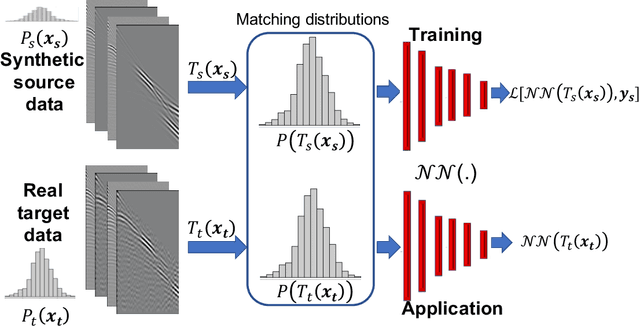
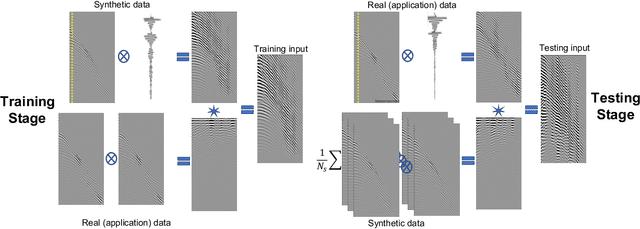
Among the biggest challenges we face in utilizing neural networks trained on waveform data (i.e., seismic, electromagnetic, or ultrasound) is its application to real data. The requirement for accurate labels forces us to develop solutions using synthetic data, where labels are readily available. However, synthetic data often do not capture the reality of the field/real experiment, and we end up with poor performance of the trained neural network (NN) at the inference stage. We describe a novel approach to enhance supervised training on synthetic data with real data features (domain adaptation). Specifically, for tasks in which the absolute values of the vertical axis (time or depth) of the input data are not crucial, like classification, or can be corrected afterward, like velocity model building using a well-log, we suggest a series of linear operations on the input so the training and application data have similar distributions. This is accomplished by applying two operations on the input data to the NN model: 1) The crosscorrelation of the input data (i.e., shot gather, seismic image, etc.) with a fixed reference trace from the same dataset. 2) The convolution of the resulting data with the mean (or a random sample) of the autocorrelated data from another domain. In the training stage, the input data are from the synthetic domain and the auto-correlated data are from the real domain, and random samples from real data are drawn at every training epoch. In the inference/application stage, the input data are from the real subset domain and the mean of the autocorrelated sections are from the synthetic data subset domain. Example applications on passive seismic data for microseismic event source location determination and active seismic data for predicting low frequencies are used to demonstrate the power of this approach in improving the applicability of trained models to real data.
Direct domain adaptation through reciprocal linear transformations
Aug 17, 2021
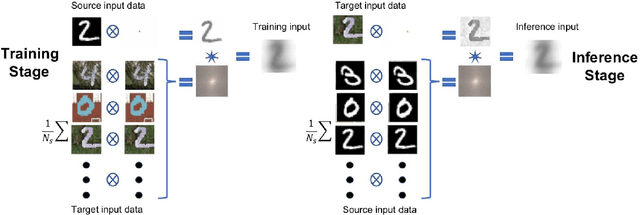
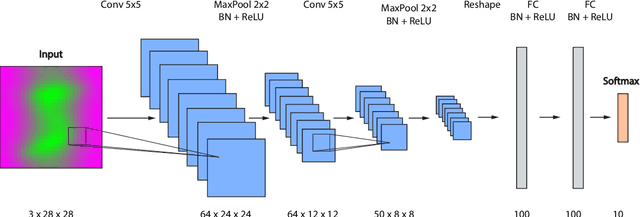

We propose a direct domain adaptation (DDA) approach to enrich the training of supervised neural networks on synthetic data by features from real-world data. The process involves a series of linear operations on the input features to the NN model, whether they are from the source or target domains, as follows: 1) A cross-correlation of the input data (i.e. images) with a randomly picked sample pixel (or pixels) of all images from that domain or the mean of all randomly picked sample pixel (or pixels) of all images. 2) The convolution of the resulting data with the mean of the autocorrelated input images from the other domain. In the training stage, as expected, the input images are from the source domain, and the mean of auto-correlated images are evaluated from the target domain. In the inference/application stage, the input images are from the target domain, and the mean of auto-correlated images are evaluated from the source domain. The proposed method only manipulates the data from the source and target domains and does not explicitly interfere with the training workflow and network architecture. An application that includes training a convolutional neural network on the MNIST dataset and testing the network on the MNIST-M dataset achieves a 70% accuracy on the test data. A principal component analysis (PCA), as well as t-SNE, show that the input features from the source and target domains, after the proposed direct transformations, share similar properties along with the principal components as compared to the original MNIST and MNIST-M input features.