 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLost in Translation: Modern Neural Networks Still Struggle With Small Realistic Image Transformations
Apr 10, 2024Deep neural networks that achieve remarkable performance in image classification have previously been shown to be easily fooled by tiny transformations such as a one pixel translation of the input image. In order to address this problem, two approaches have been proposed in recent years. The first approach suggests using huge datasets together with data augmentation in the hope that a highly varied training set will teach the network to learn to be invariant. The second approach suggests using architectural modifications based on sampling theory to deal explicitly with image translations. In this paper, we show that these approaches still fall short in robustly handling 'natural' image translations that simulate a subtle change in camera orientation. Our findings reveal that a mere one-pixel translation can result in a significant change in the predicted image representation for approximately 40% of the test images in state-of-the-art models (e.g. open-CLIP trained on LAION-2B or DINO-v2) , while models that are explicitly constructed to be robust to cyclic translations can still be fooled with 1 pixel realistic (non-cyclic) translations 11% of the time. We present Robust Inference by Crop Selection: a simple method that can be proven to achieve any desired level of consistency, although with a modest tradeoff with the model's accuracy. Importantly, we demonstrate how employing this method reduces the ability to fool state-of-the-art models with a 1 pixel translation to less than 5% while suffering from only a 1% drop in classification accuracy. Additionally, we show that our method can be easy adjusted to deal with circular shifts as well. In such case we achieve 100% robustness to integer shifts with state-of-the-art accuracy, and with no need for any further training.
Some Grammatical Errors are Frequent, Others are Important
May 11, 2022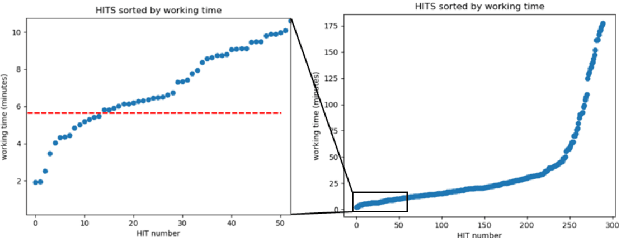
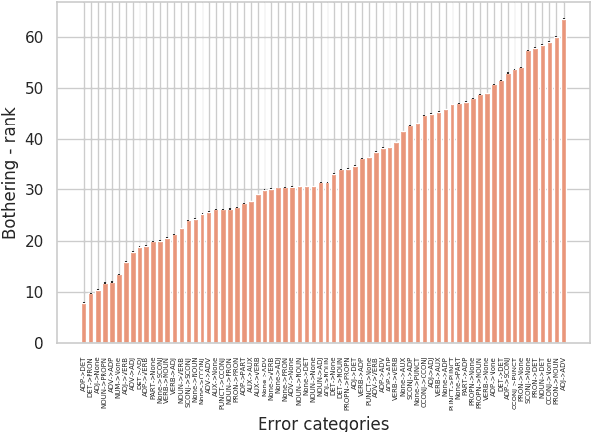

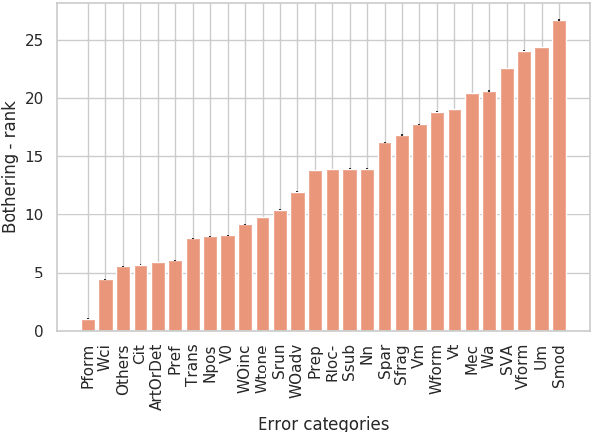
In Grammatical Error Correction, systems are evaluated by the number of errors they correct. However, no one has assessed whether all error types are equally important. We provide and apply a method to quantify the importance of different grammatical error types to humans. We show that some rare errors are considered disturbing while other common ones are not. This affects possible directions to improve both systems and their evaluation.