 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Data Driven Resource Allocation under Multi-Armed Bandit Observations
Dec 13, 2018This paper introduces the first asymptotically optimal strategy for a multi armed bandit (MAB) model under side constraints. The side constraints model situations in which bandit activations are limited by the availability of certain resources that are replenished at a constant rate. The main result involves the derivation of an asymptotic lower bound for the regret of feasible uniformly fast policies and the construction of policies that achieve this lower bound, under pertinent conditions. Further, we provide the explicit form of such policies for the case in which the unknown distributions are Normal with unknown means and known variances, for the case of Normal distributions with unknown means and unknown variances and for the case of arbitrary discrete distributions with finite support.
Asymptotically Optimal Multi-Armed Bandit Policies under a Cost Constraint
Dec 17, 2015We develop asymptotically optimal policies for the multi armed bandit (MAB), problem, under a cost constraint. This model is applicable in situations where each sample (or activation) from a population (bandit) incurs a known bandit dependent cost. Successive samples from each population are iid random variables with unknown distribution. The objective is to design a feasible policy for deciding from which population to sample from, so as to maximize the expected sum of outcomes of $n$ total samples or equivalently to minimize the regret due to lack on information on sample distributions, For this problem we consider the class of feasible uniformly fast (f-UF) convergent policies, that satisfy the cost constraint sample-path wise. We first establish a necessary asymptotic lower bound for the rate of increase of the regret function of f-UF policies. Then we construct a class of f-UF policies and provide conditions under which they are asymptotically optimal within the class of f-UF policies, achieving this asymptotic lower bound. At the end we provide the explicit form of such policies for the case in which the unknown distributions are Normal with unknown means and known variances.
Adaptive Policies for Sequential Sampling under Incomplete Information and a Cost Constraint
Jan 19, 2012
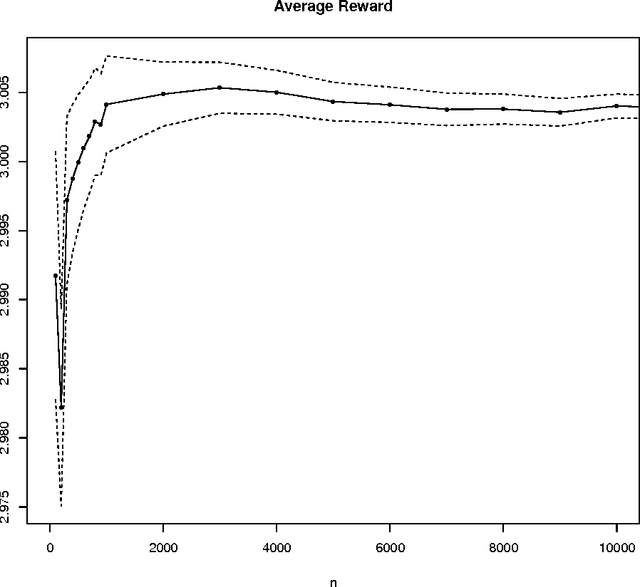
We consider the problem of sequential sampling from a finite number of independent statistical populations to maximize the expected infinite horizon average outcome per period, under a constraint that the expected average sampling cost does not exceed an upper bound. The outcome distributions are not known. We construct a class of consistent adaptive policies, under which the average outcome converges with probability 1 to the true value under complete information for all distributions with finite means. We also compare the rate of convergence for various policies in this class using simulation.