Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Policies for Sequential Sampling under Incomplete Information and a Cost Constraint
Jan 19, 2012
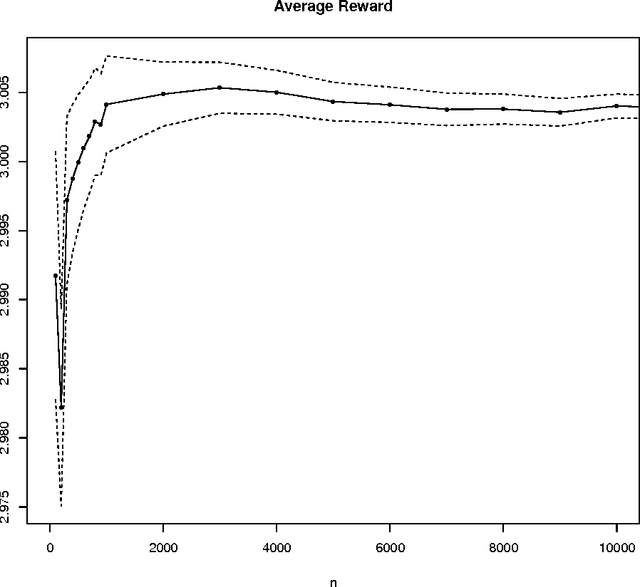
We consider the problem of sequential sampling from a finite number of independent statistical populations to maximize the expected infinite horizon average outcome per period, under a constraint that the expected average sampling cost does not exceed an upper bound. The outcome distributions are not known. We construct a class of consistent adaptive policies, under which the average outcome converges with probability 1 to the true value under complete information for all distributions with finite means. We also compare the rate of convergence for various policies in this class using simulation.
Via