 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Deep Convolutional Neural Networks with Resistive Cross-Point Devices
May 22, 2017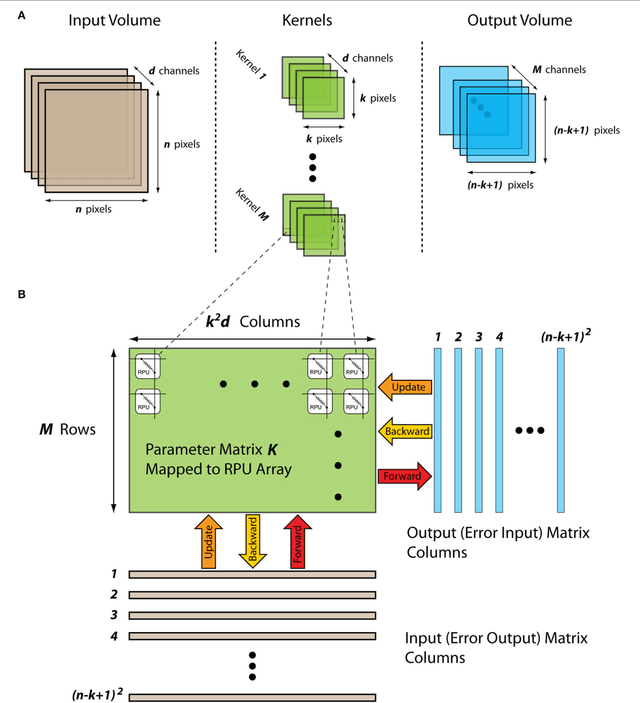

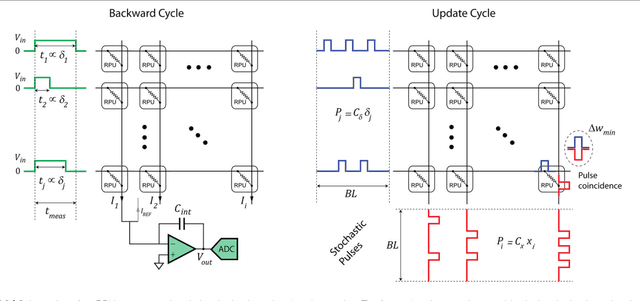
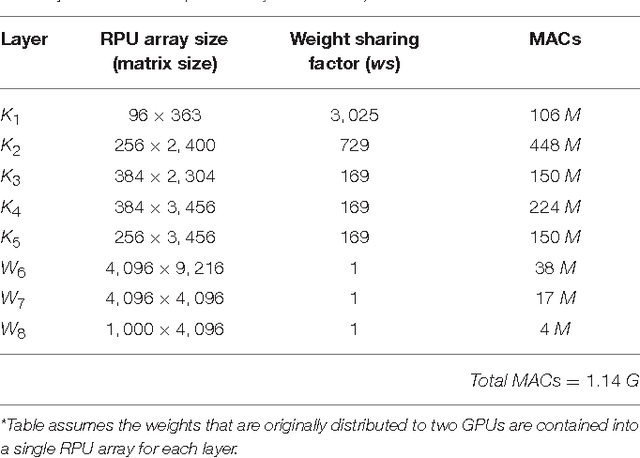
In a previous work we have detailed the requirements to obtain a maximal performance benefit by implementing fully connected deep neural networks (DNN) in form of arrays of resistive devices for deep learning. This concept of Resistive Processing Unit (RPU) devices we extend here towards convolutional neural networks (CNNs). We show how to map the convolutional layers to RPU arrays such that the parallelism of the hardware can be fully utilized in all three cycles of the backpropagation algorithm. We find that the noise and bound limitations imposed due to analog nature of the computations performed on the arrays effect the training accuracy of the CNNs. Noise and bound management techniques are presented that mitigate these problems without introducing any additional complexity in the analog circuits and can be addressed by the digital circuits. In addition, we discuss digitally programmable update management and device variability reduction techniques that can be used selectively for some of the layers in a CNN. We show that combination of all those techniques enables a successful application of the RPU concept for training CNNs. The techniques discussed here are more general and can be applied beyond CNN architectures and therefore enables applicability of RPU approach for large class of neural network architectures.