 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond One World: Benchmarking Super Heros in Role-Playing Across Multiversal Contexts
Oct 16, 2025Large language models (LLMs) are increasingly used as role-playing agents, yet their capacity to faithfully and consistently portray version-specific characters -- for example, superheroes across comic and cinematic universes -- remains underexplored. Superhero canons such as Marvel and DC provide a rich testbed: decades of storytelling yield multiple incarnations of the same character with distinct histories, values, and moral codes. To study this problem, we introduce Beyond One World, a benchmark for character-grounded roleplay spanning 30 iconic heroes and 90 canon-specific versions. The benchmark comprises two tasks: (i) Canon Events, which probes factual recall of pivotal life stages, and (ii) Moral Dilemmas, which confronts models with ethically charged scenarios. We score responses for canonical accuracy and reasoning fidelity under a framework that separates internal deliberation ("thinking") from outward decisions ("acting"). We further propose Think-Act Matching, a metric that quantifies alignment between reasons and actions and serves as a proxy for model trustworthiness. Experiments across reasoning- and non-reasoning-oriented models yield three findings: (1) chain-of-thought prompting improves narrative coherence in weaker models but can reduce canonical accuracy in stronger ones; (2) cross-version generalization within a character remains a major obstacle; and (3) models often excel at either thinking or acting, but rarely both. Beyond One World exposes critical gaps in multiversal consistency and reasoning alignment, offering a challenging evaluation for role-playing LLMs.
A Graphical Model of Hurricane Evacuation Behaviors
Nov 16, 2023Natural disasters such as hurricanes are increasing and causing widespread devastation. People's decisions and actions regarding whether to evacuate or not are critical and have a large impact on emergency planning and response. Our interest lies in computationally modeling complex relationships among various factors influencing evacuation decisions. We conducted a study on the evacuation of Hurricane Irma of the 2017 Atlantic hurricane season. The study was guided by the Protection motivation theory (PMT), a widely-used framework to understand people's responses to potential threats. Graphical models were constructed to represent the complex relationships among the factors involved and the evacuation decision. We evaluated different graphical structures based on conditional independence tests using Irma data. The final model largely aligns with PMT. It shows that both risk perception (threat appraisal) and difficulties in evacuation (coping appraisal) influence evacuation decisions directly and independently. Certain information received from media was found to influence risk perception, and through it influence evacuation behaviors indirectly. In addition, several variables were found to influence both risk perception and evacuation behaviors directly, including family and friends' suggestions, neighbors' evacuation behaviors, and evacuation notices from officials.
Investigating Large Language Models' Perception of Emotion Using Appraisal Theory
Oct 03, 2023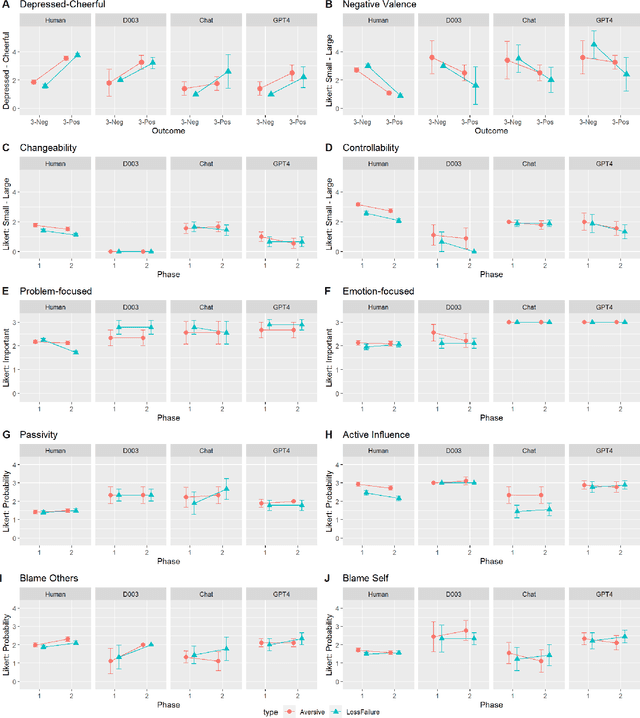
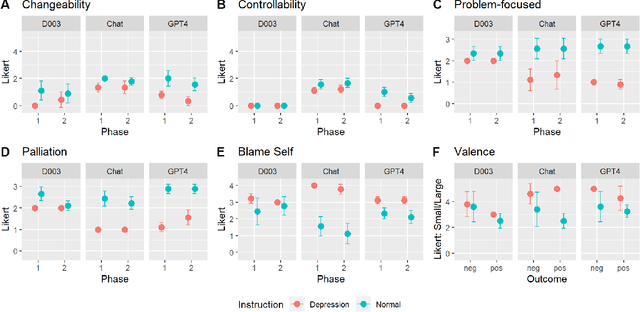
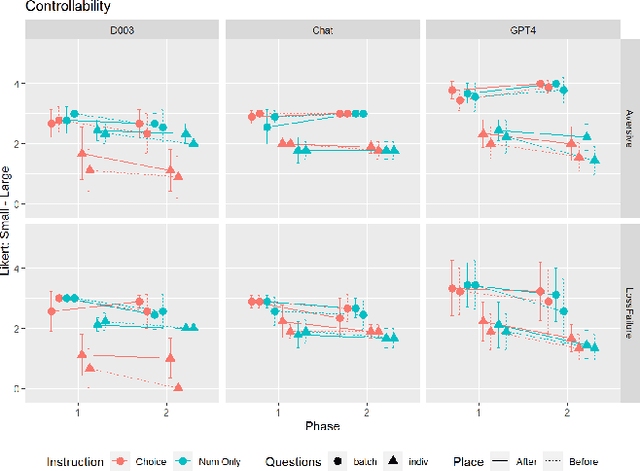
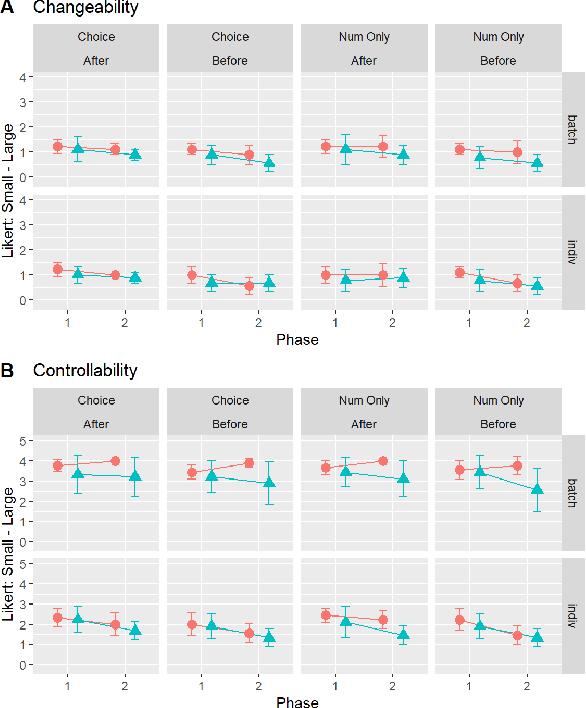
Large Language Models (LLM) like ChatGPT have significantly advanced in recent years and are now being used by the general public. As more people interact with these systems, improving our understanding of these black box models is crucial, especially regarding their understanding of human psychological aspects. In this work, we investigate their emotion perception through the lens of appraisal and coping theory using the Stress and Coping Process Questionaire (SCPQ). SCPQ is a validated clinical instrument consisting of multiple stories that evolve over time and differ in key appraisal variables such as controllability and changeability. We applied SCPQ to three recent LLMs from OpenAI, davinci-003, ChatGPT, and GPT-4 and compared the results with predictions from the appraisal theory and human data. The results show that LLMs' responses are similar to humans in terms of dynamics of appraisal and coping, but their responses did not differ along key appraisal dimensions as predicted by the theory and data. The magnitude of their responses is also quite different from humans in several variables. We also found that GPTs can be quite sensitive to instruction and how questions are asked. This work adds to the growing literature evaluating the psychological aspects of LLMs and helps enrich our understanding of the current models.