 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Safety Assurance for Deep Reinforcement Learning
Oct 07, 2020
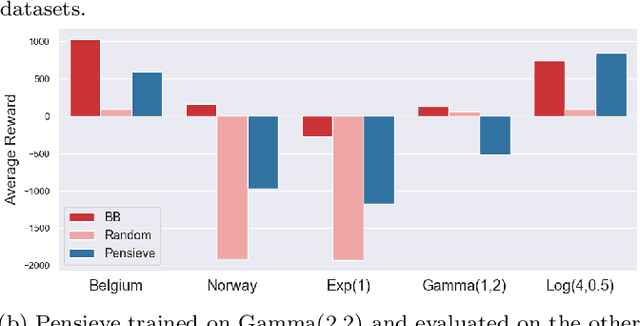


Recently, deep learning has been successfully applied to a variety of networking problems. A fundamental challenge is that when the operational environment for a learning-augmented system differs from its training environment, such systems often make badly informed decisions, leading to bad performance. We argue that safely deploying learning-driven systems requires being able to determine, in real time, whether system behavior is coherent, for the purpose of defaulting to a reasonable heuristic when this is not so. We term this the online safety assurance problem (OSAP). We present three approaches to quantifying decision uncertainty that differ in terms of the signal used to infer uncertainty. We illustrate the usefulness of online safety assurance in the context of the proposed deep reinforcement learning (RL) approach to video streaming. While deep RL for video streaming bests other approaches when the operational and training environments match, it is dominated by simple heuristics when the two differ. Our preliminary findings suggest that transitioning to a default policy when decision uncertainty is detected is key to enjoying the performance benefits afforded by leveraging ML without compromising on safety.