 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Adaptation to Non-Stationary Environments via Latent Trend Embedding for Robotics
Mar 11, 2026Robotic systems operating in real-world environments often suffer from concept shift, where the input-output relationship changes due to latent environmental factors that are not directly observable. Conventional adaptation methods update model parameters, which may cause catastrophic forgetting and incur high computational cost. This paper proposes a latent Trend ID-based framework for few-shot adaptation in non-stationary environments. Instead of modifying model weights, a low-dimensional environmental state, referred to as the Trend ID, is estimated via backpropagation while the model parameters remain fixed. To prevent overfitting caused by per-sample latent variables, we introduce temporal regularization and a state transition model that enforces smooth evolution of the latent space. Experiments on a quantitative food grasping task demonstrate that the learned Trend IDs are distributed across distinct regions of the latent space with temporally consistent trajectories, and that few-shot adaptation to unseen environments is achieved without modifying model parameters. The proposed framework provides a scalable and interpretable solution for robotics applications operating across diverse and evolving environments.
Vision + Language Applications: A Survey
May 24, 2023Text-to-image generation has attracted significant interest from researchers and practitioners in recent years due to its widespread and diverse applications across various industries. Despite the progress made in the domain of vision and language research, the existing literature remains relatively limited, particularly with regard to advancements and applications in this field. This paper explores a relevant research track within multimodal applications, including text, vision, audio, and others. In addition to the studies discussed in this paper, we are also committed to continually updating the latest relevant papers, datasets, application projects and corresponding information at https://github.com/Yutong-Zhou-cv/Awesome-Text-to-Image
Transform Invariant Auto-encoder
Sep 12, 2017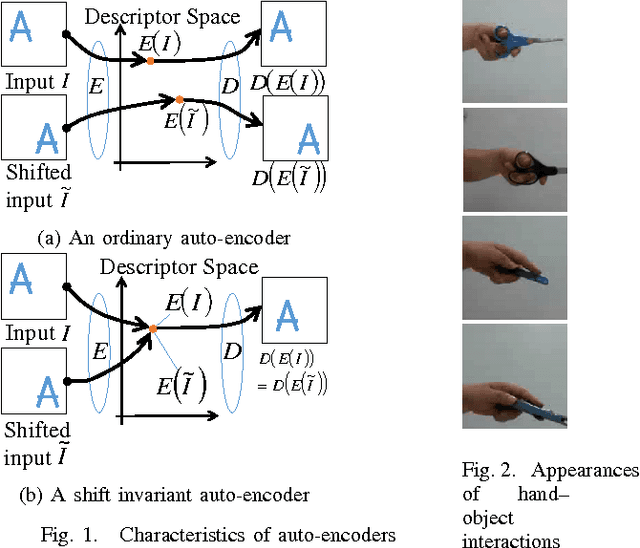

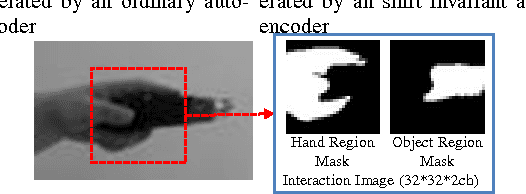
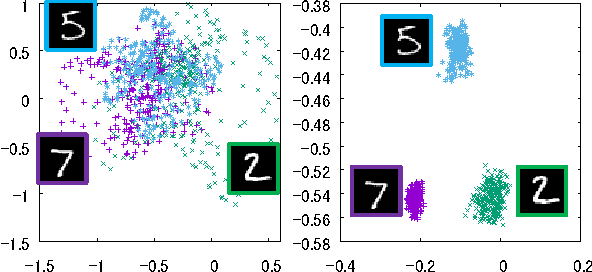
The auto-encoder method is a type of dimensionality reduction method. A mapping from a vector to a descriptor that represents essential information can be automatically generated from a set of vectors without any supervising information. However, an image and its spatially shifted version are encoded into different descriptors by an existing ordinary auto-encoder because each descriptor includes a spatial subpattern and its position. To generate a descriptor representing a spatial subpattern in an image, we need to normalize its spatial position in the images prior to training an ordinary auto-encoder; however, such a normalization is generally difficult for images without obvious standard positions. We propose a transform invariant auto-encoder and an inference model of transform parameters. By the proposed method, we can separate an input into a transform invariant descriptor and transform parameters. The proposed method can be applied to various auto-encoders without requiring any special modules or labeled training samples. By applying it to shift transforms, we can achieve a shift invariant auto-encoder that can extract a typical spatial subpattern independent of its relative position in a window. In addition, we can achieve a model that can infer shift parameters required to restore the input from the typical subpattern. As an example of the proposed method, we demonstrate that a descriptor generated by a shift invariant auto-encoder can represent a typical spatial subpattern. In addition, we demonstrate the imitation of a human hand by a robot hand as an example of a regression based on spatial subpatterns.
Construction of Latent Descriptor Space and Inference Model of Hand-Object Interactions
Sep 12, 2017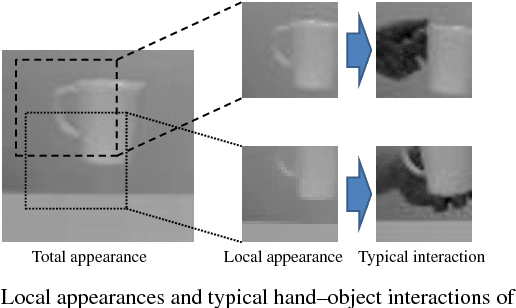

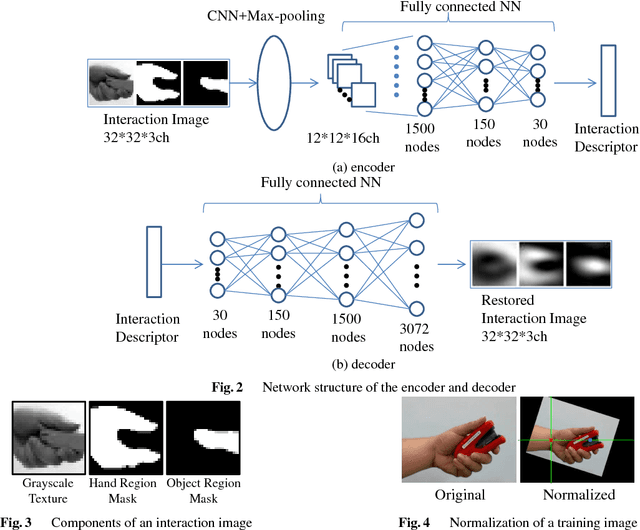

Appearance-based generic object recognition is a challenging problem because all possible appearances of objects cannot be registered, especially as new objects are produced every day. Function of objects, however, has a comparatively small number of prototypes. Therefore, function-based classification of new objects could be a valuable tool for generic object recognition. Object functions are closely related to hand-object interactions during handling of a functional object; i.e., how the hand approaches the object, which parts of the object and contact the hand, and the shape of the hand during interaction. Hand-object interactions are helpful for modeling object functions. However, it is difficult to assign discrete labels to interactions because an object shape and grasping hand-postures intrinsically have continuous variations. To describe these interactions, we propose the interaction descriptor space which is acquired from unlabeled appearances of human hand-object interactions. By using interaction descriptors, we can numerically describe the relation between an object's appearance and its possible interaction with the hand. The model infers the quantitative state of the interaction from the object image alone. It also identifies the parts of objects designed for hand interactions such as grips and handles. We demonstrate that the proposed method can unsupervisedly generate interaction descriptors that make clusters corresponding to interaction types. And also we demonstrate that the model can infer possible hand-object interactions.