 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransform Invariant Auto-encoder
Sep 12, 2017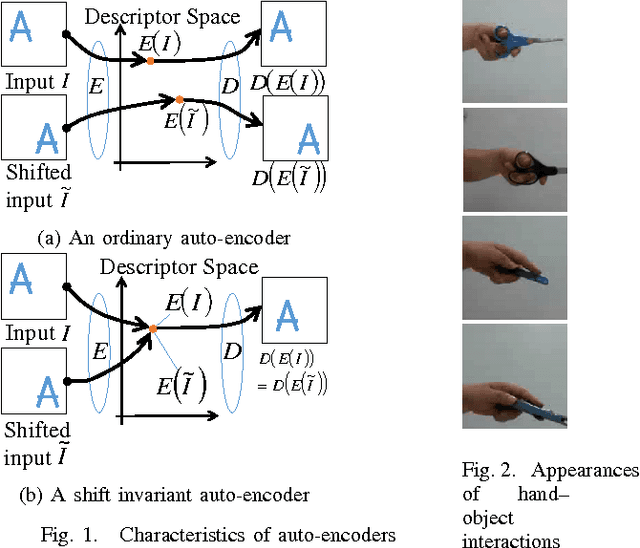

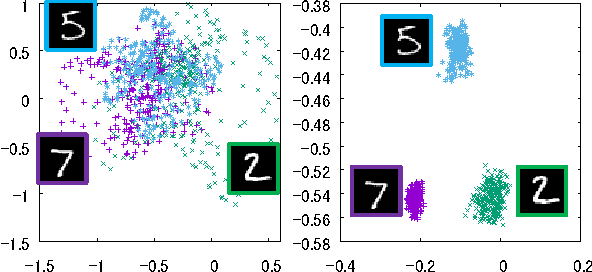
The auto-encoder method is a type of dimensionality reduction method. A mapping from a vector to a descriptor that represents essential information can be automatically generated from a set of vectors without any supervising information. However, an image and its spatially shifted version are encoded into different descriptors by an existing ordinary auto-encoder because each descriptor includes a spatial subpattern and its position. To generate a descriptor representing a spatial subpattern in an image, we need to normalize its spatial position in the images prior to training an ordinary auto-encoder; however, such a normalization is generally difficult for images without obvious standard positions. We propose a transform invariant auto-encoder and an inference model of transform parameters. By the proposed method, we can separate an input into a transform invariant descriptor and transform parameters. The proposed method can be applied to various auto-encoders without requiring any special modules or labeled training samples. By applying it to shift transforms, we can achieve a shift invariant auto-encoder that can extract a typical spatial subpattern independent of its relative position in a window. In addition, we can achieve a model that can infer shift parameters required to restore the input from the typical subpattern. As an example of the proposed method, we demonstrate that a descriptor generated by a shift invariant auto-encoder can represent a typical spatial subpattern. In addition, we demonstrate the imitation of a human hand by a robot hand as an example of a regression based on spatial subpatterns.