 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Topic Extraction via Graph-Based Labeling: A Lightweight Alternative to Deep Models
Nov 06, 2025



Extracting topics from text has become an essential task, especially with the rapid growth of unstructured textual data. Most existing works rely on highly computational methods to address this challenge. In this paper, we argue that probabilistic and statistical approaches, such as topic modeling (TM), can offer effective alternatives that require fewer computational resources. TM is a statistical method that automatically discovers topics in large collections of unlabeled text; however, it produces topics as distributions of representative words, which often lack clear interpretability. Our objective is to perform topic labeling by assigning meaningful labels to these sets of words. To achieve this without relying on computationally expensive models, we propose a graph-based approach that not only enriches topic words with semantically related terms but also explores the relationships among them. By analyzing these connections within the graph, we derive suitable labels that accurately capture each topic's meaning. We present a comparative study between our proposed method and several benchmarks, including ChatGPT-3.5, across two different datasets. Our method achieved consistently better results than traditional benchmarks in terms of BERTScore and cosine similarity and produced results comparable to ChatGPT-3.5, while remaining computationally efficient. Finally, we discuss future directions for topic labeling and highlight potential research avenues for enhancing interpretability and automation.
Overcoming Data Scarcity in Generative Language Modelling for Low-Resource Languages: A Systematic Review
May 07, 2025Generative language modelling has surged in popularity with the emergence of services such as ChatGPT and Google Gemini. While these models have demonstrated transformative potential in productivity and communication, they overwhelmingly cater to high-resource languages like English. This has amplified concerns over linguistic inequality in natural language processing (NLP). This paper presents the first systematic review focused specifically on strategies to address data scarcity in generative language modelling for low-resource languages (LRL). Drawing from 54 studies, we identify, categorise and evaluate technical approaches, including monolingual data augmentation, back-translation, multilingual training, and prompt engineering, across generative tasks. We also analyse trends in architecture choices, language family representation, and evaluation methods. Our findings highlight a strong reliance on transformer-based models, a concentration on a small subset of LRLs, and a lack of consistent evaluation across studies. We conclude with recommendations for extending these methods to a wider range of LRLs and outline open challenges in building equitable generative language systems. Ultimately, this review aims to support researchers and developers in building inclusive AI tools for underrepresented languages, a necessary step toward empowering LRL speakers and the preservation of linguistic diversity in a world increasingly shaped by large-scale language technologies.
Bridging Gaps in Natural Language Processing for Yorùbá: A Systematic Review of a Decade of Progress and Prospects
Feb 24, 2025Natural Language Processing (NLP) is becoming a dominant subset of artificial intelligence as the need to help machines understand human language looks indispensable. Several NLP applications are ubiquitous, partly due to the myriads of datasets being churned out daily through mediums like social networking sites. However, the growing development has not been evident in most African languages due to the persisting resource limitation, among other issues. Yor\`ub\'a language, a tonal and morphologically rich African language, suffers a similar fate, resulting in limited NLP usage. To encourage further research towards improving this situation, this systematic literature review aims to comprehensively analyse studies addressing NLP development for Yor\`ub\'a, identifying challenges, resources, techniques, and applications. A well-defined search string from a structured protocol was employed to search, select, and analyse 105 primary studies between 2014 and 2024 from reputable databases. The review highlights the scarcity of annotated corpora, limited availability of pre-trained language models, and linguistic challenges like tonal complexity and diacritic dependency as significant obstacles. It also revealed the prominent techniques, including rule-based methods, among others. The findings reveal a growing body of multilingual and monolingual resources, even though the field is constrained by socio-cultural factors such as code-switching and desertion of language for digital usage. This review synthesises existing research, providing a foundation for advancing NLP for Yor\`ub\'a and in African languages generally. It aims to guide future research by identifying gaps and opportunities, thereby contributing to the broader inclusion of Yor\`ub\'a and other under-resourced African languages in global NLP advancements.
Towards Utilising a Range of Neural Activations for Comprehending Representational Associations
Nov 15, 2024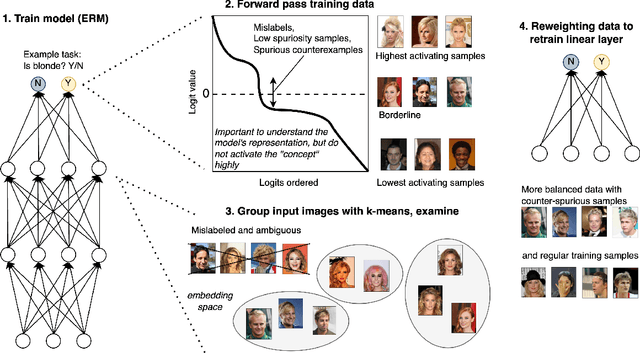
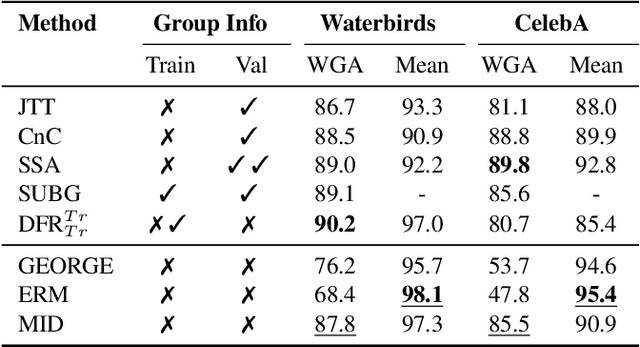
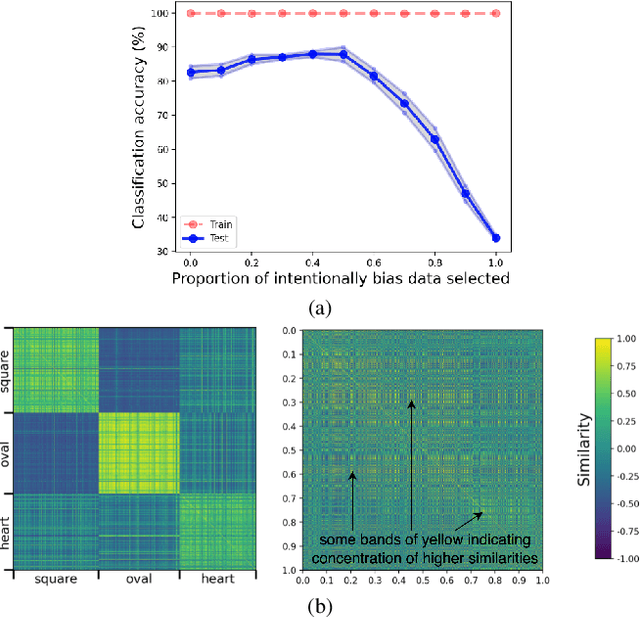
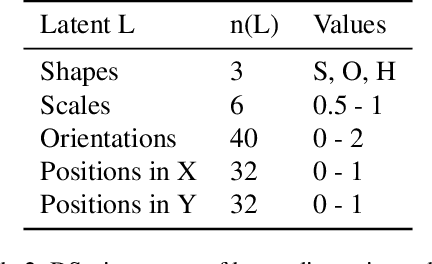
Recent efforts to understand intermediate representations in deep neural networks have commonly attempted to label individual neurons and combinations of neurons that make up linear directions in the latent space by examining extremal neuron activations and the highest direction projections. In this paper, we show that this approach, although yielding a good approximation for many purposes, fails to capture valuable information about the behaviour of a representation. Neural network activations are generally dense, and so a more complex, but realistic scenario is that linear directions encode information at various levels of stimulation. We hypothesise that non-extremal level activations contain complex information worth investigating, such as statistical associations, and thus may be used to locate confounding human interpretable concepts. We explore the value of studying a range of neuron activations by taking the case of mid-level output neuron activations and demonstrate on a synthetic dataset how they can inform us about aspects of representations in the penultimate layer not evident through analysing maximal activations alone. We use our findings to develop a method to curate data from mid-range logit samples for retraining to mitigate spurious correlations, or confounding concepts in the penultimate layer, on real benchmark datasets. The success of our method exemplifies the utility of inspecting non-maximal activations to extract complex relationships learned by models.
Bridging the gap in online hate speech detection: a comparative analysis of BERT and traditional models for homophobic content identification on X/Twitter
May 15, 2024Our study addresses a significant gap in online hate speech detection research by focusing on homophobia, an area often neglected in sentiment analysis research. Utilising advanced sentiment analysis models, particularly BERT, and traditional machine learning methods, we developed a nuanced approach to identify homophobic content on X/Twitter. This research is pivotal due to the persistent underrepresentation of homophobia in detection models. Our findings reveal that while BERT outperforms traditional methods, the choice of validation technique can impact model performance. This underscores the importance of contextual understanding in detecting nuanced hate speech. By releasing the largest open-source labelled English dataset for homophobia detection known to us, an analysis of various models' performance and our strongest BERT-based model, we aim to enhance online safety and inclusivity. Future work will extend to broader LGBTQIA+ hate speech detection, addressing the challenges of sourcing diverse datasets. Through this endeavour, we contribute to the larger effort against online hate, advocating for a more inclusive digital landscape. Our study not only offers insights into the effective detection of homophobic content by improving on previous research results, but it also lays groundwork for future advancements in hate speech analysis.
On the Detection of Anomalous or Out-Of-Distribution Data in Vision Models Using Statistical Techniques
Mar 21, 2024Out-of-distribution data and anomalous inputs are vulnerabilities of machine learning systems today, often causing systems to make incorrect predictions. The diverse range of data on which these models are used makes detecting atypical inputs a difficult and important task. We assess a tool, Benford's law, as a method used to quantify the difference between real and corrupted inputs. We believe that in many settings, it could function as a filter for anomalous data points and for signalling out-of-distribution data. We hope to open a discussion on these applications and further areas where this technique is underexplored.
UserReg: A Simple but Strong Model for Rating Prediction
Feb 15, 2021
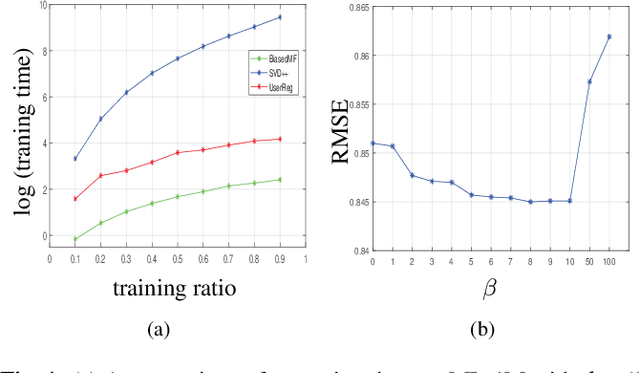
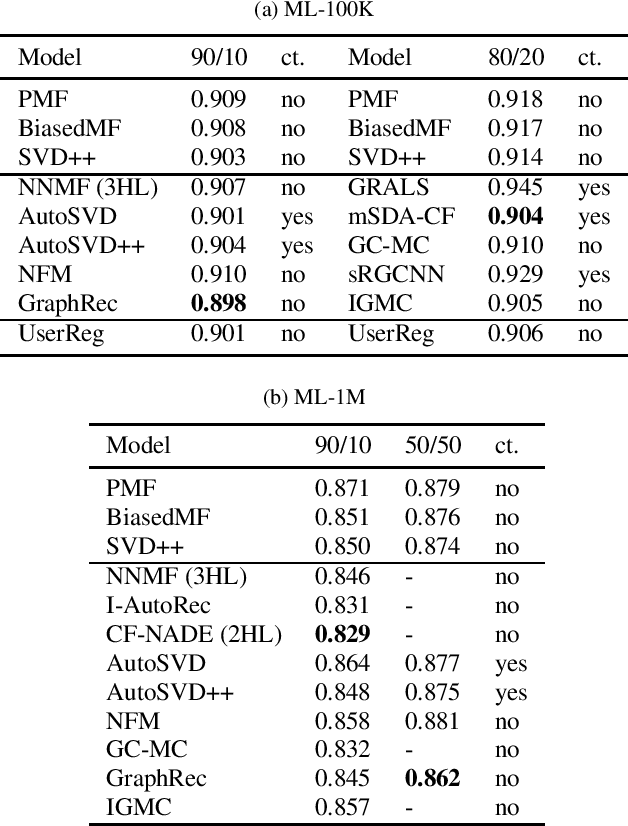

Collaborative filtering (CF) has achieved great success in the field of recommender systems. In recent years, many novel CF models, particularly those based on deep learning or graph techniques, have been proposed for a variety of recommendation tasks, such as rating prediction and item ranking. These newly published models usually demonstrate their performance in comparison to baselines or existing models in terms of accuracy improvements. However, others have pointed out that many newly proposed models are not as strong as expected and are outperformed by very simple baselines. This paper proposes a simple linear model based on Matrix Factorization (MF), called UserReg, which regularizes users' latent representations with explicit feedback information for rating prediction. We compare the effectiveness of UserReg with three linear CF models that are widely-used as baselines, and with a set of recently proposed complex models that are based on deep learning or graph techniques. Experimental results show that UserReg achieves overall better performance than the fine-tuned baselines considered and is highly competitive when compared with other recently proposed models. We conclude that UserReg can be used as a strong baseline for future CF research.