 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Data Efficient End-To-End Spoken Language Understanding Architecture
Feb 14, 2020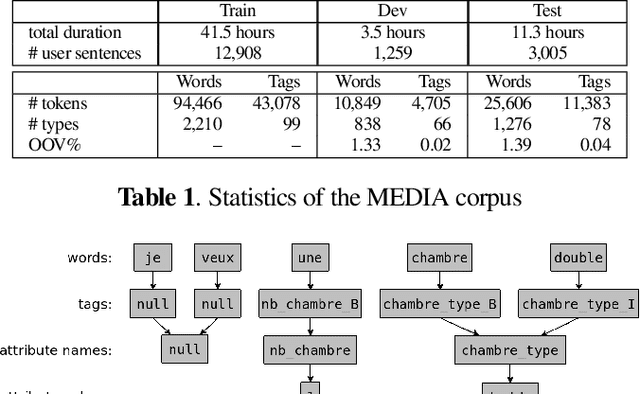
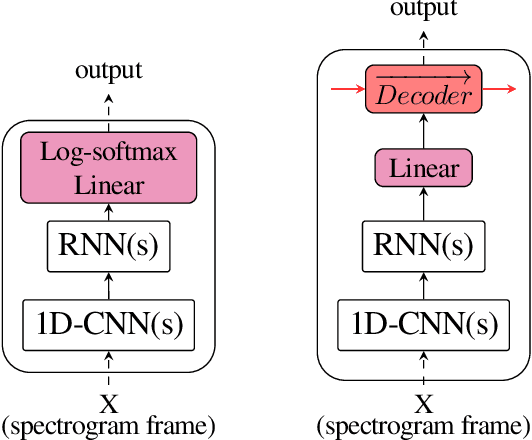
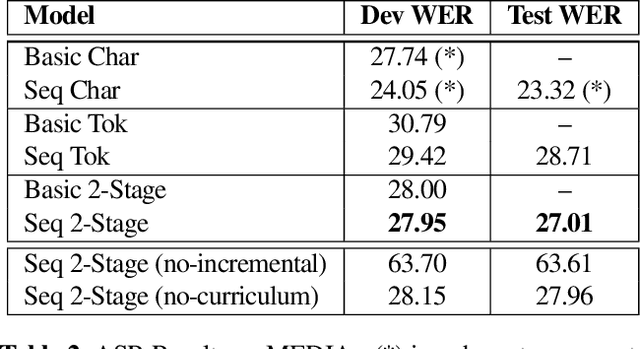
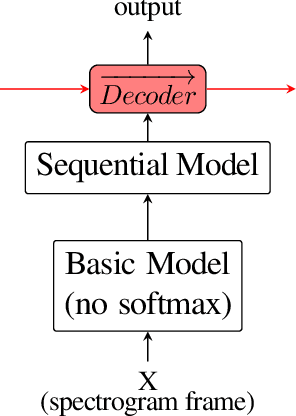
End-to-end architectures have been recently proposed for spoken language understanding (SLU) and semantic parsing. Based on a large amount of data, those models learn jointly acoustic and linguistic-sequential features. Such architectures give very good results in the context of domain, intent and slot detection, their application in a more complex semantic chunking and tagging task is less easy. For that, in many cases, models are combined with an external language model to enhance their performance. In this paper we introduce a data efficient system which is trained end-to-end, with no additional, pre-trained external module. One key feature of our approach is an incremental training procedure where acoustic, language and semantic models are trained sequentially one after the other. The proposed model has a reasonable size and achieves competitive results with respect to state-of-the-art while using a small training dataset. In particular, we reach 24.02% Concept Error Rate (CER) on MEDIA/test while training on MEDIA/train without any additional data.