 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep representation of EEG data from Spatio-Spectral Feature Images
Jun 20, 2022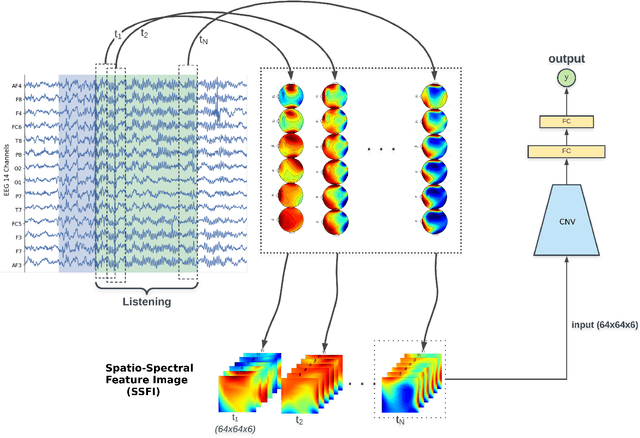
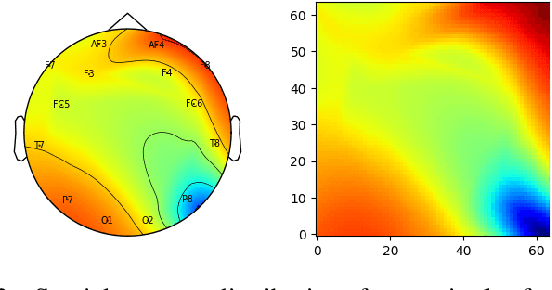
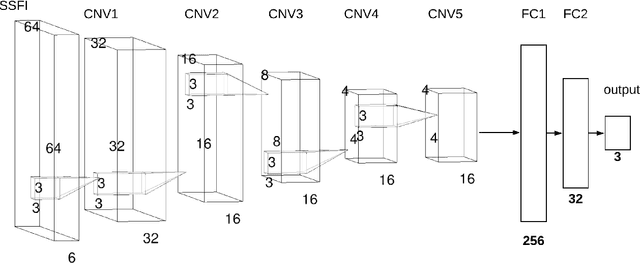
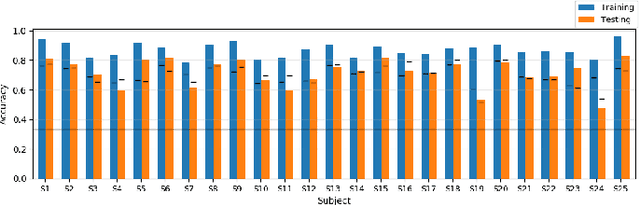
Unlike conventional data such as natural images, audio and speech, raw multi-channel Electroencephalogram (EEG) data are difficult to interpret. Modern deep neural networks have shown promising results in EEG studies, however finding robust invariant representations of EEG data across subjects remains a challenge, due to differences in brain folding structures. Thus, invariant representations of EEG data would be desirable to improve our understanding of the brain activity and to use them effectively during transfer learning. In this paper, we propose an approach to learn deep representations of EEG data by exploiting spatial relationships between recording electrodes and encoding them in a Spatio-Spectral Feature Images. We use multi-channel EEG signals from the PhyAAt dataset for auditory tasks and train a Convolutional Neural Network (CNN) on 25 subjects individually. Afterwards, we generate the input patterns that activate deep neurons across all the subjects. The generated pattern can be seen as a map of the brain activity in different spatial regions. Our analysis reveals the existence of specific brain regions related to different tasks. Low-level features focusing on larger regions and high-level features focusing on a smaller and very specific cluster of regions are also identified. Interestingly, similar patterns are found across different subjects although the activities appear in different regions. Our analysis also reveals common brain regions across subjects, which can be used as generalized representations. Our proposed approach allows us to find more interpretable representations of EEG data, which can further be used for effective transfer learning.
PhyAAt: Physiology of Auditory Attention to Speech Dataset
May 23, 2020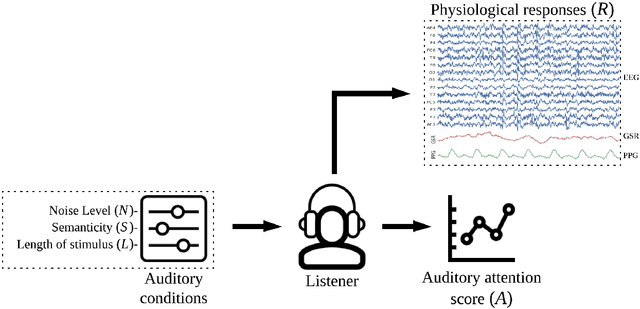

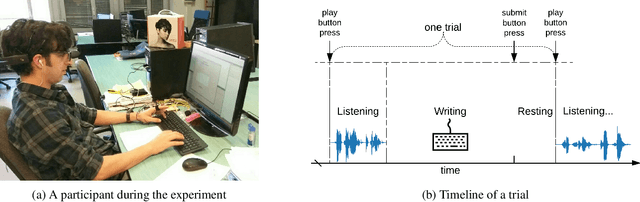
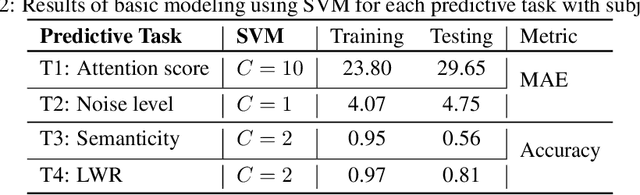
Auditory attention to natural speech is a complex brain process. Its quantification from physiological signals can be valuable to improving and widening the range of applications of current brain-computer-interface systems, however it remains a challenging task. In this article, we present a dataset of physiological signals collected from an experiment on auditory attention to natural speech. In this experiment, auditory stimuli consisting of reproductions of English sentences in different auditory conditions were presented to 25 non-native participants, who were asked to transcribe the sentences. During the experiment, 14 channel electroencephalogram, galvanic skin response, and photoplethysmogram signals were collected from each participant. Based on the number of correctly transcribed words, an attention score was obtained for each auditory stimulus presented to subjects. A strong correlation ($p<<0.0001$) between the attention score and the auditory conditions was found. We also formulate four different predictive tasks involving the collected dataset and develop a feature extraction framework. The results for each predictive task are obtained using a Support Vector Machine with spectral features, and are better than chance level. The dataset has been made publicly available for further research, along with a python library - phyaat to facilitate the preprocessing, modeling, and reproduction of the results presented in this paper. The dataset and other resources are shared on webpage - https://phyaat.github.io.
Fraud detection in telephone conversations for financial services using linguistic features
Dec 10, 2019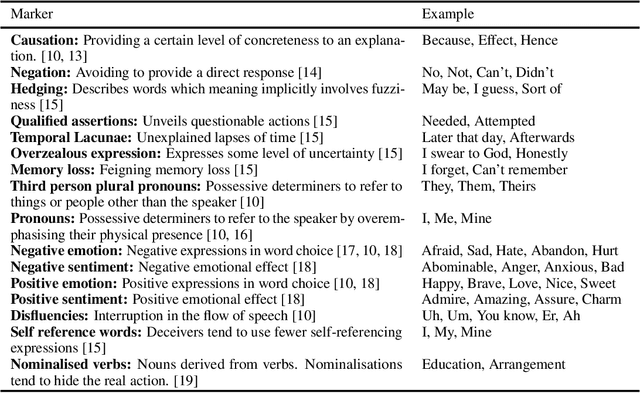

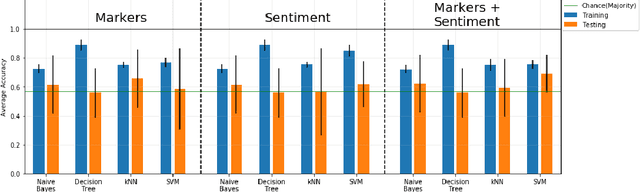
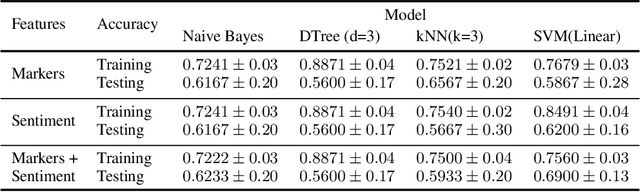
Detecting the elements of deception in a conversation is one of the most challenging problems for the AI community. It becomes even more difficult to design a transparent system, which is fully explainable and satisfies the need for financial and legal services to be deployed. This paper presents an approach for fraud detection in transcribed telephone conversations using linguistic features. The proposed approach exploits the syntactic and semantic information of the transcription to extract both the linguistic markers and the sentiment of the customer's response. We demonstrate the results on real-world financial services data using simple, robust and explainable classifiers such as Naive Bayes, Decision Tree, Nearest Neighbours, and Support Vector Machines.