 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgefeather -- a Python SDK to share and deploy models
Aug 05, 2023
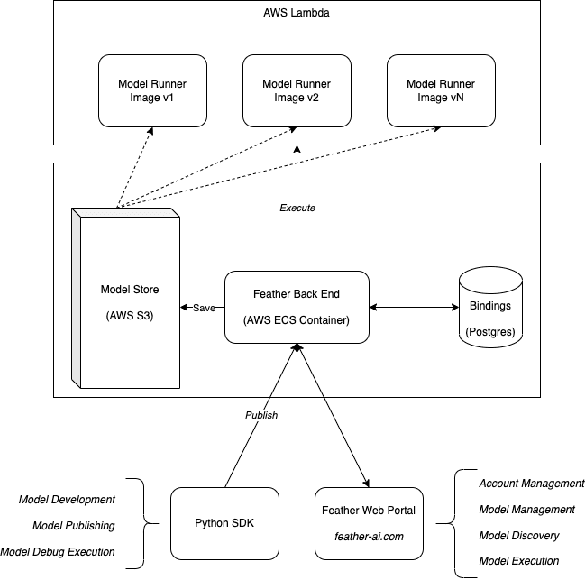

At its core, feather was a tool that allowed model developers to build shareable user interfaces for their models in under 20 lines of code. Using the Python SDK, developers specified visual components that users would interact with. (e.g. a FileUpload component to allow users to upload a file). Our service then provided 1) a URL that allowed others to access and use the model visually via a user interface; 2) an API endpoint to allow programmatic requests to a model. In this paper, we discuss feather's motivations and the value we intended to offer AI researchers and developers. For example, the SDK can support multi-step models and can be extended to run automatic evaluation against held out datasets. We additionally provide comprehensive technical and implementation details. N.B. feather is presently a dormant project. We have open sourced our code for research purposes: https://github.com/feather-ai/
Guiding Visual Question Generation
Oct 15, 2021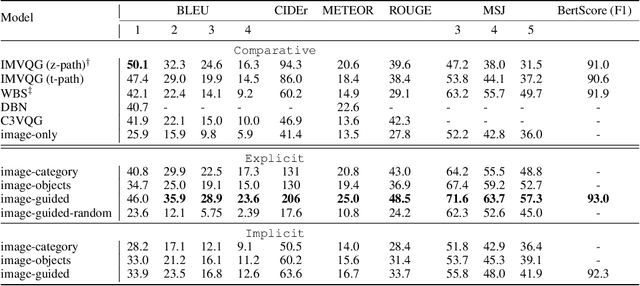
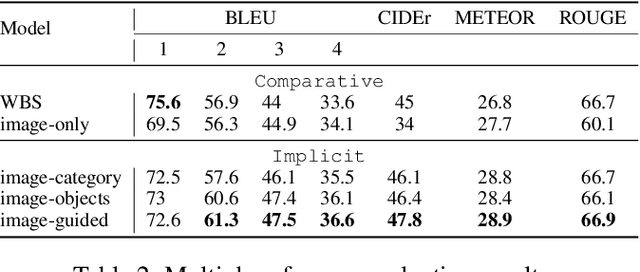


In traditional Visual Question Generation (VQG), most images have multiple concepts (e.g. objects and categories) for which a question could be generated, but models are trained to mimic an arbitrary choice of concept as given in their training data. This makes training difficult and also poses issues for evaluation -- multiple valid questions exist for most images but only one or a few are captured by the human references. We present Guiding Visual Question Generation - a variant of VQG which conditions the question generator on categorical information based on expectations on the type of question and the objects it should explore. We propose two variants: (i) an explicitly guided model that enables an actor (human or automated) to select which objects and categories to generate a question for; and (ii) an implicitly guided model that learns which objects and categories to condition on, based on discrete latent variables. The proposed models are evaluated on an answer-category augmented VQA dataset and our quantitative results show a substantial improvement over the current state of the art (over 9 BLEU-4 increase). Human evaluation validates that guidance helps the generation of questions that are grammatically coherent and relevant to the given image and objects.