 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWarming-up recurrent neural networks to maximize reachable multi-stability greatly improves learning
Jun 02, 2021



Training recurrent neural networks is known to be difficult when time dependencies become long. Consequently, training standard gated cells such as gated recurrent units and long-short term memory on benchmarks where long-term memory is required remains an arduous task. In this work, we propose a general way to initialize any recurrent network connectivity through a process called "warm-up" to improve its capability to learn arbitrarily long time dependencies. This initialization process is designed to maximize network reachable multi-stability, i.e. the number of attractors within the network that can be reached through relevant input trajectories. Warming-up is performed before training, using stochastic gradient descent on a specifically designed loss. We show that warming-up greatly improves recurrent neural network performance on long-term memory benchmarks for multiple recurrent cell types, but can sometimes impede precision. We therefore introduce a parallel recurrent network structure with partial warm-up that is shown to greatly improve learning on long time-series while maintaining high levels of precision. This approach provides a general framework for improving learning abilities of any recurrent cell type when long-term memory is required.
A bio-inspired bistable recurrent cell allows for long-lasting memory
Jun 09, 2020



Recurrent neural networks (RNNs) provide state-of-the-art performances in a wide variety of tasks that require memory. These performances can often be achieved thanks to gated recurrent cells such as gated recurrent units (GRU) and long short-term memory (LSTM). Standard gated cells share a layer internal state to store information at the network level, and long term memory is shaped by network-wide recurrent connection weights. Biological neurons on the other hand are capable of holding information at the cellular level for an arbitrary long amount of time through a process called bistability. Through bistability, cells can stabilize to different stable states depending on their own past state and inputs, which permits the durable storing of past information in neuron state. In this work, we take inspiration from biological neuron bistability to embed RNNs with long-lasting memory at the cellular level. This leads to the introduction of a new bistable biologically-inspired recurrent cell that is shown to strongly improves RNN performance on time-series which require very long memory, despite using only cellular connections (all recurrent connections are from neurons to themselves, i.e. a neuron state is not influenced by the state of other neurons). Furthermore, equipping this cell with recurrent neuromodulation permits to link them to standard GRU cells, taking a step towards the biological plausibility of GRU.
Introducing Neuromodulation in Deep Neural Networks to Learn Adaptive Behaviours
Jan 02, 2019

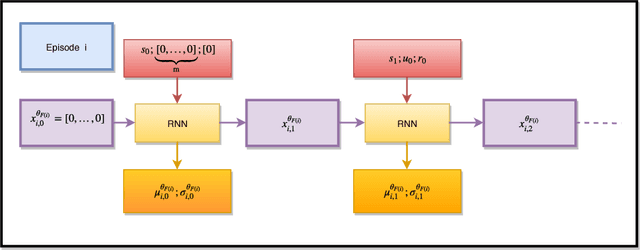

In this paper, we propose a new deep neural network architecture, called NMD net, that has been specifically designed to learn adaptive behaviours. This architecture exploits a biological mechanism called neuromodulation that sustains adaptation in biological organisms. This architecture has been introduced in a deep-reinforcement learning architecture for interacting with Markov decision processes in a meta-reinforcement learning setting where the action space is continuous. The deep-reinforcement learning architecture is trained using an advantage actor-critic algorithm. Experiments are carried on several test problems. Results show that the neural network architecture with neuromodulation provides significantly better results than state-of-the-art recurrent neural networks which do not exploit this mechanism.