 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fused Large Language Model for Predicting Startup Success
Sep 05, 2024



Investors are continuously seeking profitable investment opportunities in startups and, hence, for effective decision-making, need to predict a startup's probability of success. Nowadays, investors can use not only various fundamental information about a startup (e.g., the age of the startup, the number of founders, and the business sector) but also textual description of a startup's innovation and business model, which is widely available through online venture capital (VC) platforms such as Crunchbase. To support the decision-making of investors, we develop a machine learning approach with the aim of locating successful startups on VC platforms. Specifically, we develop, train, and evaluate a tailored, fused large language model to predict startup success. Thereby, we assess to what extent self-descriptions on VC platforms are predictive of startup success. Using 20,172 online profiles from Crunchbase, we find that our fused large language model can predict startup success, with textual self-descriptions being responsible for a significant part of the predictive power. Our work provides a decision support tool for investors to find profitable investment opportunities.
Which linguistic cues make people fall for fake news? A comparison of cognitive and affective processing
Dec 02, 2023Fake news on social media has large, negative implications for society. However, little is known about what linguistic cues make people fall for fake news and, hence, how to design effective countermeasures for social media. In this study, we seek to understand which linguistic cues make people fall for fake news. Linguistic cues (e.g., adverbs, personal pronouns, positive emotion words, negative emotion words) are important characteristics of any text and also affect how people process real vs. fake news. Specifically, we compare the role of linguistic cues across both cognitive processing (related to careful thinking) and affective processing (related to unconscious automatic evaluations). To this end, we performed a within-subject experiment where we collected neurophysiological measurements of 42 subjects while these read a sample of 40 real and fake news articles. During our experiment, we measured cognitive processing through eye fixations, and affective processing in situ through heart rate variability. We find that users engage more in cognitive processing for longer fake news articles, while affective processing is more pronounced for fake news written in analytic words. To the best of our knowledge, this is the first work studying the role of linguistic cues in fake news processing. Altogether, our findings have important implications for designing online platforms that encourage users to engage in careful thinking and thus prevent them from falling for fake news.
Integrating Floor Plans into Hedonic Models for Rent Price Appraisal
Feb 16, 2021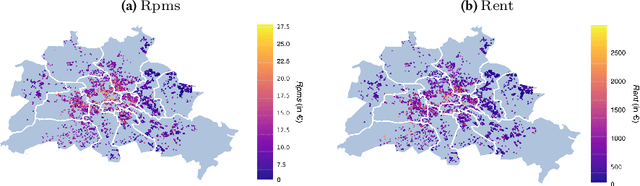
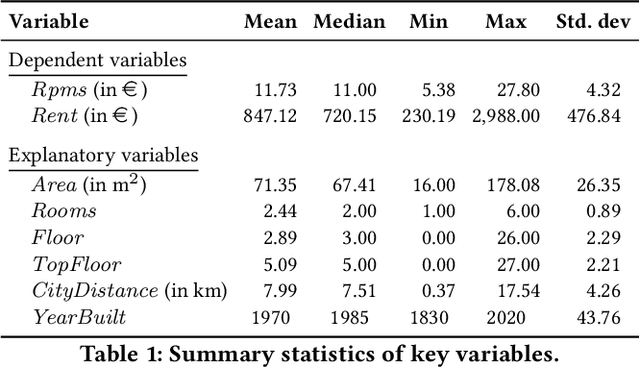
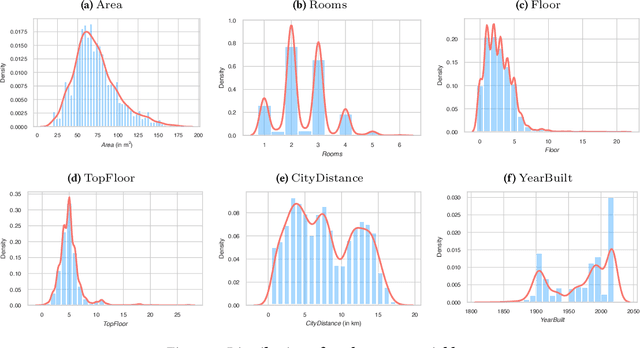
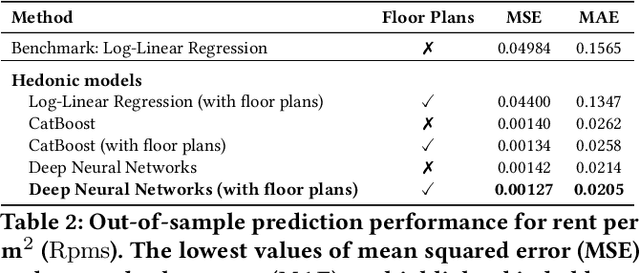
Online real estate platforms have become significant marketplaces facilitating users' search for an apartment or a house. Yet it remains challenging to accurately appraise a property's value. Prior works have primarily studied real estate valuation based on hedonic price models that take structured data into account while accompanying unstructured data is typically ignored. In this study, we investigate to what extent an automated visual analysis of apartment floor plans on online real estate platforms can enhance hedonic rent price appraisal. We propose a tailored two-staged deep learning approach to learn price-relevant designs of floor plans from historical price data. Subsequently, we integrate the floor plan predictions into hedonic rent price models that account for both structural and locational characteristics of an apartment. Our empirical analysis based on a unique dataset of 9174 real estate listings suggests that current hedonic models underutilize the available data. We find that (1) the visual design of floor plans has significant explanatory power regarding rent prices - even after controlling for structural and locational apartment characteristics, and (2) harnessing floor plans results in an up to 10.56% lower out-of-sample prediction error. We further find that floor plans yield a particularly high gain in prediction performance for older and smaller apartments. Altogether, our empirical findings contribute to the existing research body by establishing the link between the visual design of floor plans and real estate prices. Moreover, our approach has important implications for online real estate platforms, which can use our findings to enhance user experience in their real estate listings.
The Longer the Better? The Interplay Between Review Length and Line of Argumentation in Online Consumer Reviews
Sep 26, 2019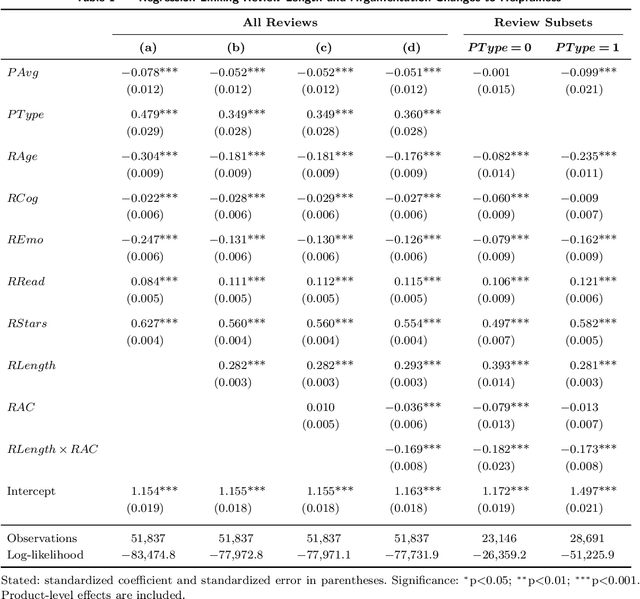
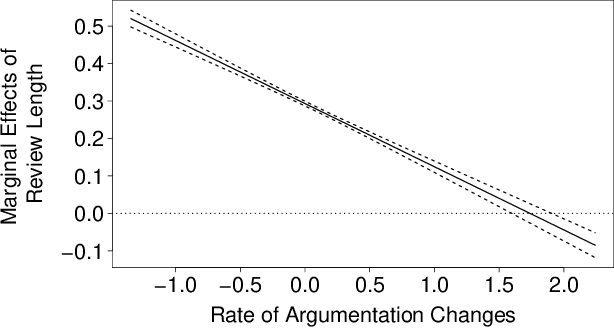
Review helpfulness serves as focal point in understanding customers' purchase decision-making process on online retailer platforms. An overwhelming majority of previous works find longer reviews to be more helpful than short reviews. In this paper, we propose that longer reviews should not be assumed to be uniformly more helpful; instead, we argue that the effect depends on the line of argumentation in the review text. To test this idea, we use a large dataset of customer reviews from Amazon in combination with a state-of-the-art approach from natural language processing that allows us to study argumentation lines at sentence level. Our empirical analysis suggests that the frequency of argumentation changes moderates the effect of review length on helpfulness. Altogether, we disprove the prevailing narrative that longer reviews are uniformly perceived as more helpful. Our findings allow retailer platforms to improve their customer feedback systems and to feature more useful product reviews.
Sentence-Level Sentiment Analysis of Financial News Using Distributed Text Representations and Multi-Instance Learning
Dec 31, 2018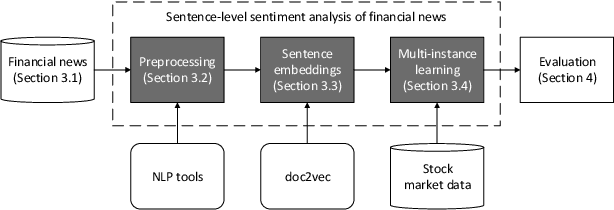
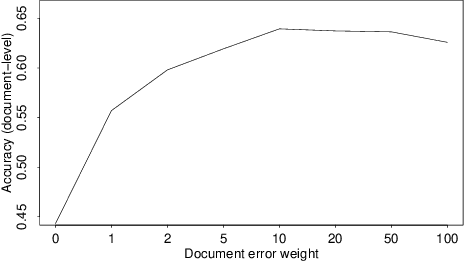


Researchers and financial professionals require robust computerized tools that allow users to rapidly operationalize and assess the semantic textual content in financial news. However, existing methods commonly work at the document-level while deeper insights into the actual structure and the sentiment of individual sentences remain blurred. As a result, investors are required to apply the utmost attention and detailed, domain-specific knowledge in order to assess the information on a fine-grained basis. To facilitate this manual process, this paper proposes the use of distributed text representations and multi-instance learning to transfer information from the document-level to the sentence-level. Compared to alternative approaches, this method features superior predictive performance while preserving context and interpretability. Our analysis of a manually-labeled dataset yields a predictive accuracy of up to 69.90%, exceeding the performance of alternative approaches by at least 3.80 percentage points. Accordingly, this study not only benefits investors with regard to their financial decision-making, but also helps companies to communicate their messages as intended.
Understanding the Role of Two-Sided Argumentation in Online Consumer Reviews: A Language-Based Perspective
Oct 25, 2018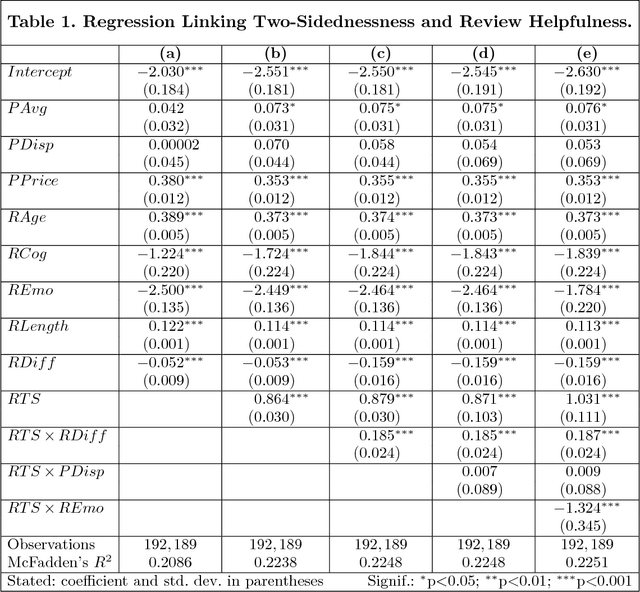
This paper examines the effect of two-sided argumentation on the perceived helpfulness of online consumer reviews. In contrast to previous works, our analysis thereby sheds light on the reception of reviews from a language-based perspective. For this purpose, we propose an intriguing text analysis approach based on distributed text representations and multi-instance learning to operationalize the two-sidedness of argumentation in review texts. A subsequent empirical analysis using a large corpus of Amazon reviews suggests that two-sided argumentation in reviews significantly increases their helpfulness. We find this effect to be stronger for positive reviews than for negative reviews, whereas a higher degree of emotional language weakens the effect. Our findings have immediate implications for retailer platforms, which can utilize our results to optimize their customer feedback system and to present more useful product reviews.
Reinforcement Learning in R
Sep 29, 2018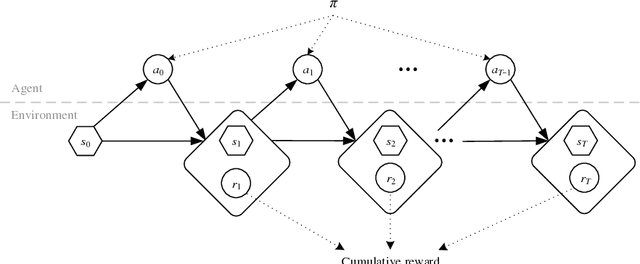
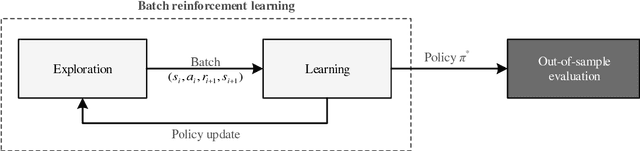
Reinforcement learning refers to a group of methods from artificial intelligence where an agent performs learning through trial and error. It differs from supervised learning, since reinforcement learning requires no explicit labels; instead, the agent interacts continuously with its environment. That is, the agent starts in a specific state and then performs an action, based on which it transitions to a new state and, depending on the outcome, receives a reward. Different strategies (e.g. Q-learning) have been proposed to maximize the overall reward, resulting in a so-called policy, which defines the best possible action in each state. Mathematically, this process can be formalized by a Markov decision process and it has been implemented by packages in R; however, there is currently no package available for reinforcement learning. As a remedy, this paper demonstrates how to perform reinforcement learning in R and, for this purpose, introduces the ReinforcementLearning package. The package provides a remarkably flexible framework and is easily applied to a wide range of different problems. We demonstrate its use by drawing upon common examples from the literature (e.g. finding optimal game strategies).
Investor Reaction to Financial Disclosures Across Topics: An Application of Latent Dirichlet Allocation
May 08, 2018


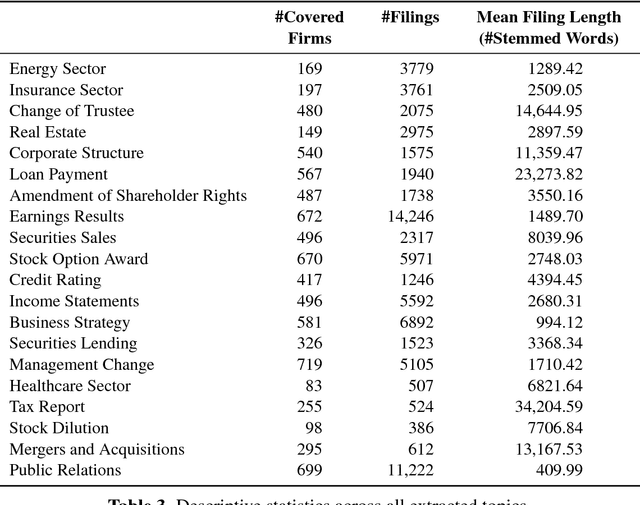
This paper provides a holistic study of how stock prices vary in their response to financial disclosures across different topics. Thereby, we specifically shed light into the extensive amount of filings for which no a priori categorization of their content exists. For this purpose, we utilize an approach from data mining - namely, latent Dirichlet allocation - as a means of topic modeling. This technique facilitates our task of automatically categorizing, ex ante, the content of more than 70,000 regulatory 8-K filings from U.S. companies. We then evaluate the subsequent stock market reaction. Our empirical evidence suggests a considerable discrepancy among various types of news stories in terms of their relevance and impact on financial markets. For instance, we find a statistically significant abnormal return in response to earnings results and credit rating, but also for disclosures regarding business strategy, the health sector, as well as mergers and acquisitions. Our results yield findings that benefit managers, investors and policy-makers by indicating how regulatory filings should be structured and the topics most likely to precede changes in stock valuations.
Statistical Inferences for Polarity Identification in Natural Language
Apr 05, 2018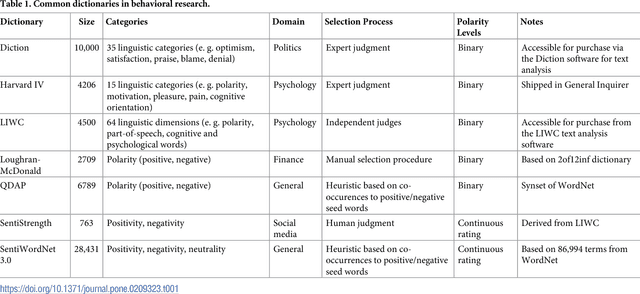
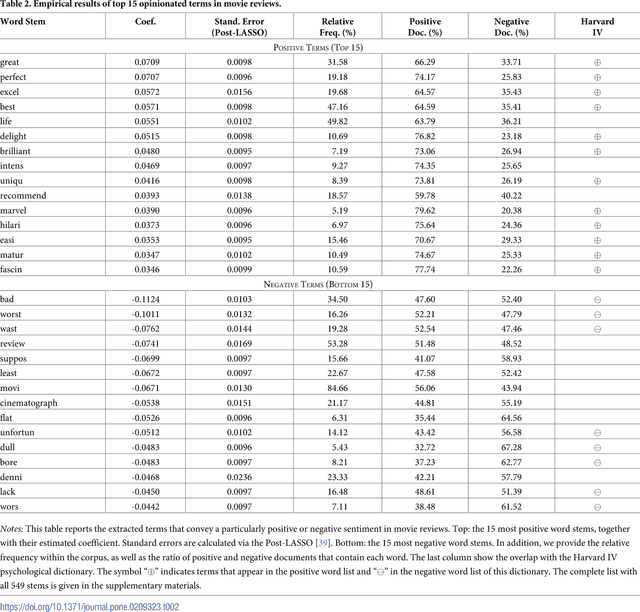
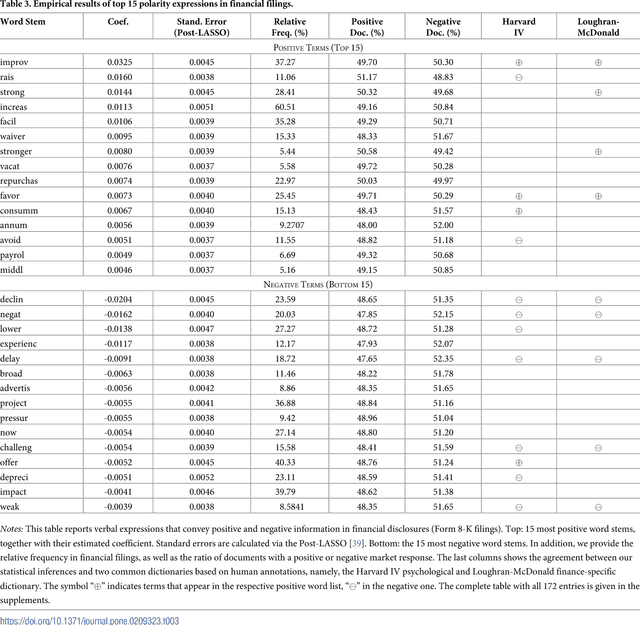
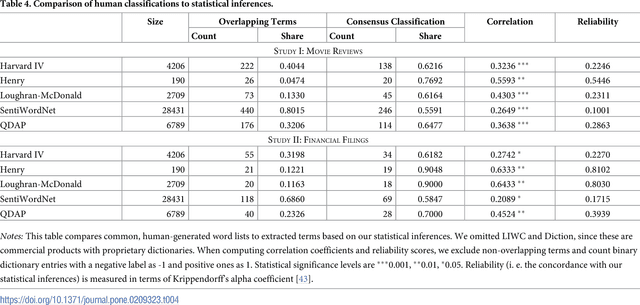
Information forms the basis for all human behavior, including the ubiquitous decision-making that people constantly perform in their every day lives. It is thus the mission of researchers to understand how humans process information to reach decisions. In order to facilitate this task, this work proposes a novel method of studying the reception of granular expressions in natural language. The approach utilizes LASSO regularization as a statistical tool to extract decisive words from textual content and draw statistical inferences based on the correspondence between the occurrences of words and an exogenous response variable. Accordingly, the method immediately suggests significant implications for social sciences and Information Systems research: everyone can now identify text segments and word choices that are statistically relevant to authors or readers and, based on this knowledge, test hypotheses from behavioral research. We demonstrate the contribution of our method by examining how authors communicate subjective information through narrative materials. This allows us to answer the question of which words to choose when communicating negative information. On the other hand, we show that investors trade not only upon facts in financial disclosures but are distracted by filler words and non-informative language. Practitioners - for example those in the fields of investor communications or marketing - can exploit our insights to enhance their writings based on the true perception of word choice.
Understanding Negations in Information Processing: Learning from Replicating Human Behavior
Apr 18, 2017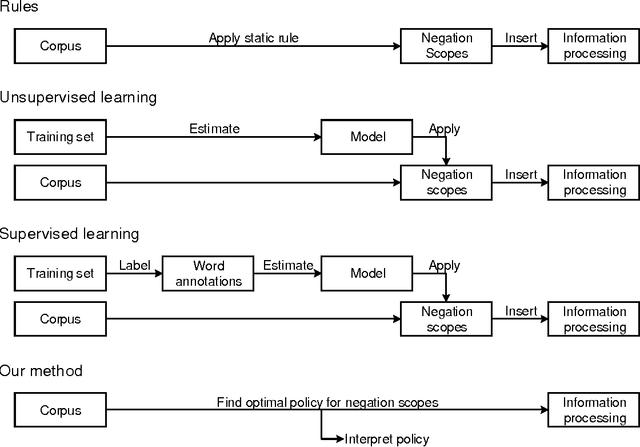

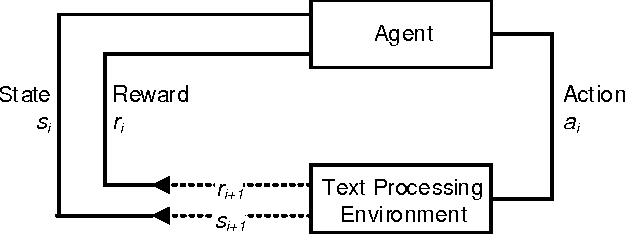

Information systems experience an ever-growing volume of unstructured data, particularly in the form of textual materials. This represents a rich source of information from which one can create value for people, organizations and businesses. For instance, recommender systems can benefit from automatically understanding preferences based on user reviews or social media. However, it is difficult for computer programs to correctly infer meaning from narrative content. One major challenge is negations that invert the interpretation of words and sentences. As a remedy, this paper proposes a novel learning strategy to detect negations: we apply reinforcement learning to find a policy that replicates the human perception of negations based on an exogenous response, such as a user rating for reviews. Our method yields several benefits, as it eliminates the former need for expensive and subjective manual labeling in an intermediate stage. Moreover, the inferred policy can be used to derive statistical inferences and implications regarding how humans process and act on negations.