 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Limits of Data Scaling: Sub-token Utilization and Acoustic Saturation in Multilingual ASR
Oct 26, 2025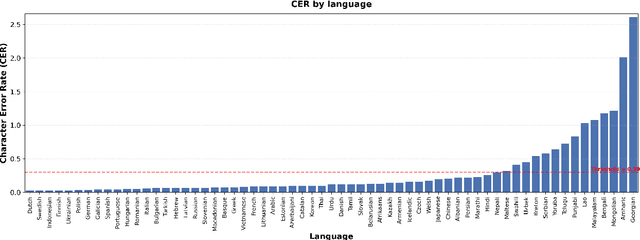
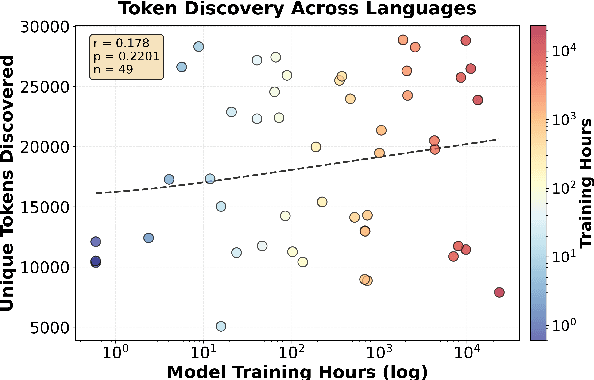
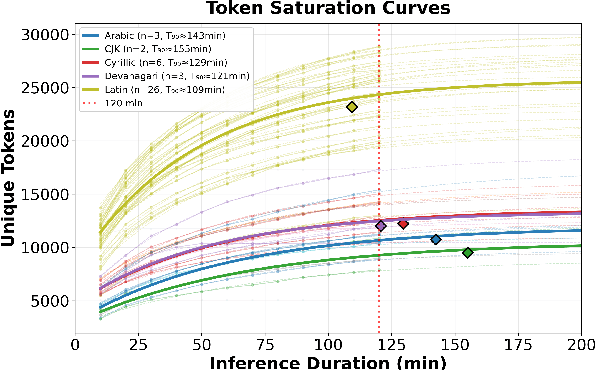
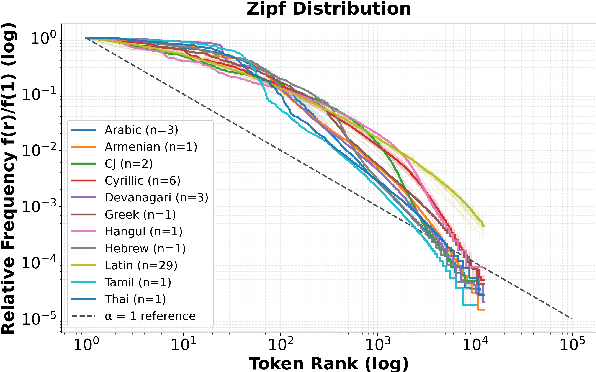
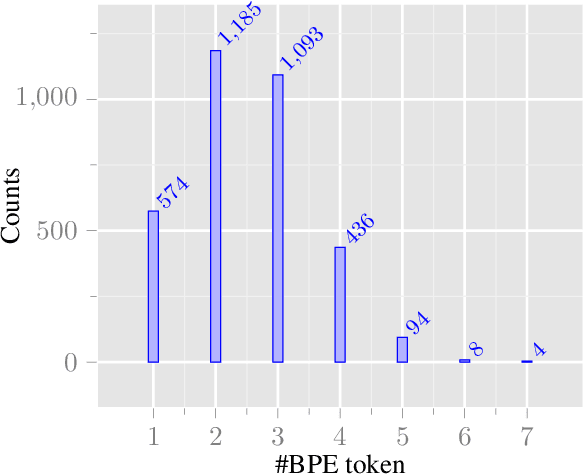
How much audio is needed to fully observe a multilingual ASR model's learned sub-token inventory across languages, and does data disparity in multilingual pre-training affect how these tokens are utilized during inference? We address this question by analyzing Whisper's decoding behavior during inference across 49 languages. By logging decoding candidate sub-tokens and tracking their cumulative discovery over time, we study the utilization pattern of the model's sub-token space. Results show that the total number of discovered tokens remains largely independent of a language's pre-training hours, indicating that data disparity does not strongly influence lexical diversity in the model's hypothesis space. Sub-token discovery rates follow a consistent exponential saturation pattern across languages, suggesting a stable time window after which additional audio yields minimal new sub-token activation. We refer to this convergence threshold as acoustic saturation time (AST). Further analyses of rank-frequency distributions reveal Zipf-like patterns better modeled by a Zipf-Mandelbrot law, and mean sub-token length shows a positive correlation with resource level. Additionally, those metrics show more favorable patterns for languages in the Latin script than those in scripts such as Cyrillic, CJK, and Semitic. Together, our study suggests that sub-token utilization during multilingual ASR inference is constrained more by the statistical, typological, and orthographic structure of the speech than by training data scale, providing an empirical basis for more equitable corpus construction and cross-lingual evaluation.
Assessing the validity of new paradigmatic complexity measures as criterial features for proficiency in L2 writings in English
Mar 13, 2025



This article addresses Second Language (L2) writing development through an investigation of new grammatical and structural complexity metrics. We explore the paradigmatic production in learner English by linking language functions to specific grammatical paradigms. Using the EFCAMDAT as a gold standard and a corpus of French learners as an external test set, we employ a supervised learning framework to operationalise and evaluate seven microsystems. We show that learner levels are associated with the seven microsystems (MS). Using ordinal regression modelling for evaluation, the results show that all MS are significant but yield a low impact if taken individually. However, their influence is shown to be impactful if taken as a group. These microsystems and their measurement method suggest that it is possible to use them as part of broader-purpose CALL systems focused on proficiency assessment.
Fine-tuning a Subtle Parsing Distinction Using a Probabilistic Decision Tree: the Case of Postnominal "that" in Noun Complement Clauses vs. Relative Clauses
Dec 05, 2022In this paper we investigated two different methods to parse relative and noun complement clauses in English and resorted to distinct tags for their corresponding that as a relative pronoun and as a complementizer. We used an algorithm to relabel a corpus parsed with the GUM Treebank using Universal Dependency. Our second experiment consisted in using TreeTagger, a Probabilistic Decision Tree, to learn the distinction between the two complement and relative uses of postnominal "that". We investigated the effect of the training set size on TreeTagger accuracy and how representative the GUM Treebank files are for the two structures under scrutiny. We discussed some of the linguistic and structural tenets of the learnability of this distinction.
Screening Gender Transfer in Neural Machine Translation
Feb 25, 2022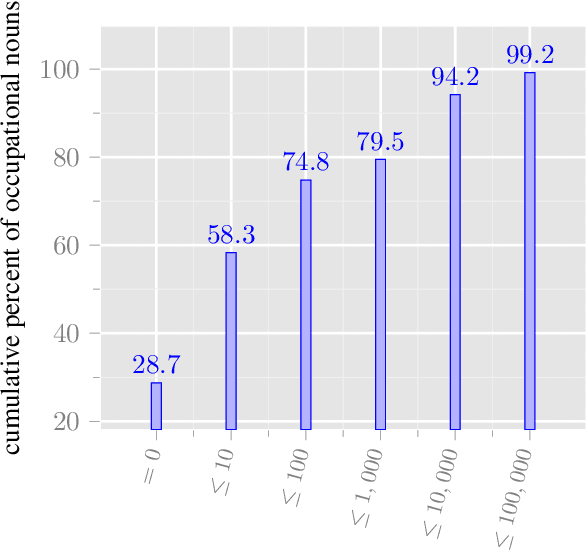


This paper aims at identifying the information flow in state-of-the-art machine translation systems, taking as example the transfer of gender when translating from French into English. Using a controlled set of examples, we experiment several ways to investigate how gender information circulates in a encoder-decoder architecture considering both probing techniques as well as interventions on the internal representations used in the MT system. Our results show that gender information can be found in all token representations built by the encoder and the decoder and lead us to conclude that there are multiple pathways for gender transfer.
Approches quantitatives de l'analyse des pr{é}dictions en traduction automatique neuronale
Dec 10, 2020


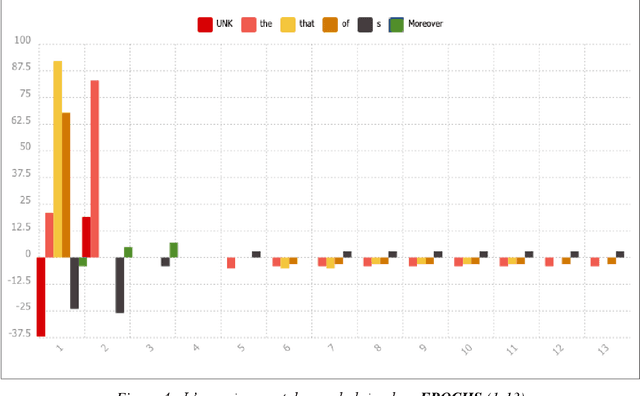
As part of a larger project on optimal learning conditions in neural machine translation, we investigate characteristic training phases of translation engines. All our experiments are carried out using OpenNMT-Py: the pre-processing step is implemented using the Europarl training corpus and the INTERSECT corpus is used for validation. Longitudinal analyses of training phases suggest that the progression of translations is not always linear. Following the results of textometric explorations, we identify the importance of the phenomena related to chronological progression, in order to map different processes at work in neural machine translation (NMT).
Predicting CEFRL levels in learner English on the basis of metrics and full texts
Jun 28, 2018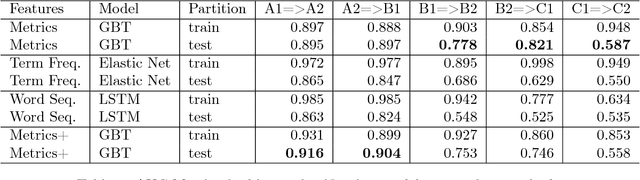
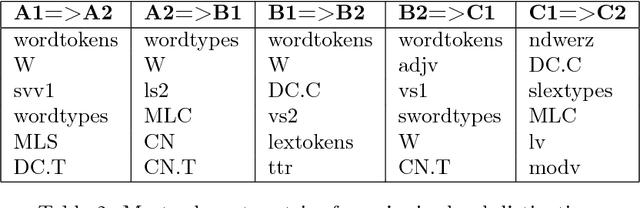
This paper analyses the contribution of language metrics and, potentially, of linguistic structures, to classify French learners of English according to levels of the Common European Framework of Reference for Languages (CEFRL). The purpose is to build a model for the prediction of learner levels as a function of language complexity features. We used the EFCAMDAT corpus, a database of one million written assignments by learners. After applying language complexity metrics on the texts, we built a representation matching the language metrics of the texts to their assigned CEFRL levels. Lexical and syntactic metrics were computed with LCA, LSA, and koRpus. Several supervised learning models were built by using Gradient Boosted Trees and Keras Neural Network methods and by contrasting pairs of CEFRL levels. Results show that it is possible to implement pairwise distinctions, especially for levels ranging from A1 to B1 (A1=>A2: 0.916 AUC and A2=>B1: 0.904 AUC). Model explanation reveals significant linguistic features for the predictiveness in the corpus. Word tokens and word types appear to play a significant role in determining levels. This shows that levels are highly dependent on specific semantic profiles.