Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproches quantitatives de l'analyse des pr{é}dictions en traduction automatique neuronale
Paper and Code



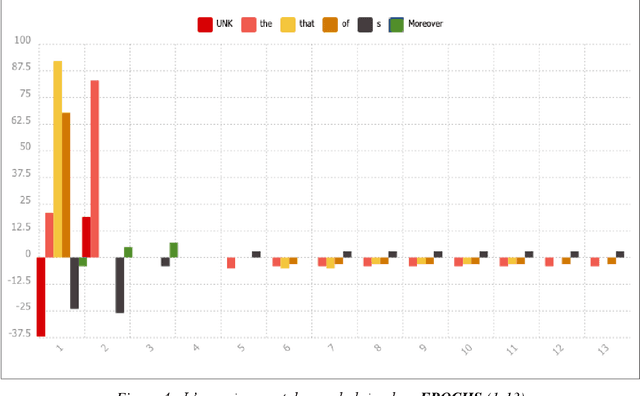
As part of a larger project on optimal learning conditions in neural machine translation, we investigate characteristic training phases of translation engines. All our experiments are carried out using OpenNMT-Py: the pre-processing step is implemented using the Europarl training corpus and the INTERSECT corpus is used for validation. Longitudinal analyses of training phases suggest that the progression of translations is not always linear. Following the results of textometric explorations, we identify the importance of the phenomena related to chronological progression, in order to map different processes at work in neural machine translation (NMT).
* in French. JADT 2020 : 15{\`e}mes Journ{\'e}es Internationales
d'Analyse statistique des Donn{\'e}es Textuelles, Universit{\'e} de Toulouse,
Jun 2020, Toulouse, France
View paper on