 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Dynamic Difficulty Adjustment in Videogames
Jul 06, 2020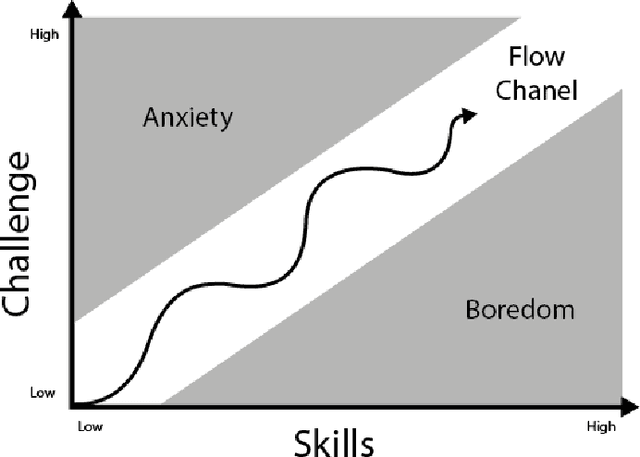
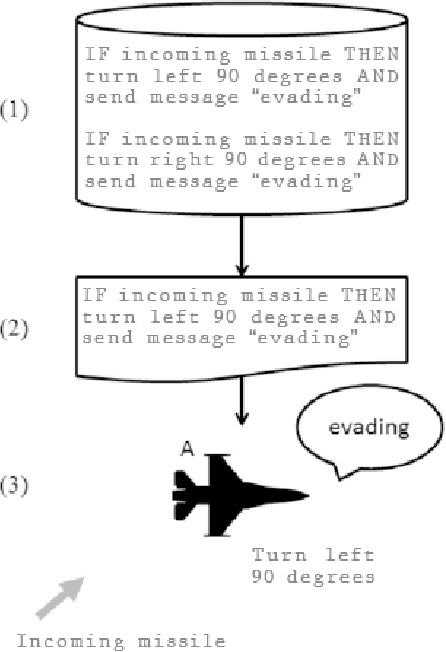
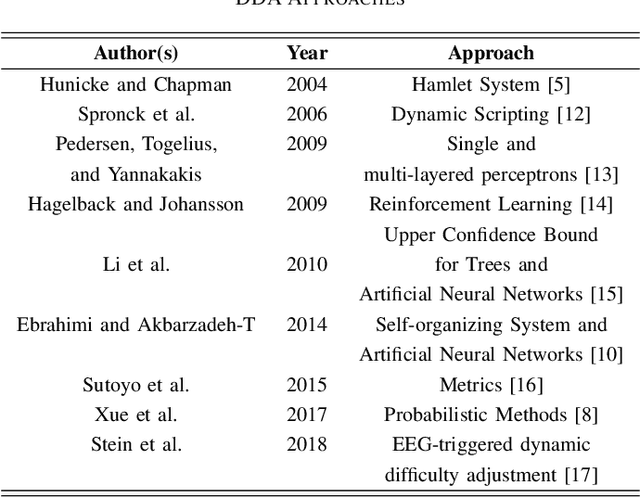
Videogames are nowadays one of the biggest entertainment industries in the world. Being part of this industry means competing against lots of other companies and developers, thus, making fanbases of vital importance. They are a group of clients that constantly support your company because your video games are fun. Videogames are most entertaining when the difficulty level is a good match for the player's skill, increasing the player engagement. However, not all players are equally proficient, so some kind of difficulty selection is required. In this paper, we will present Dynamic Difficulty Adjustment (DDA), a recently arising research topic, which aims to develop an automated difficulty selection mechanism that keeps the player engaged and properly challenged, neither bored nor overwhelmed. We will present some recent research addressing this issue, as well as an overview of how to implement it. Satisfactorily solving the DDA problem directly affects the player's experience when playing the game, making it of high interest to any game developer, from independent ones, to 100 billion dollar businesses, because of the potential impacts in player retention and monetization.
Combining Strategic Learning and Tactical Search in Real-Time Strategy Games
Sep 11, 2017

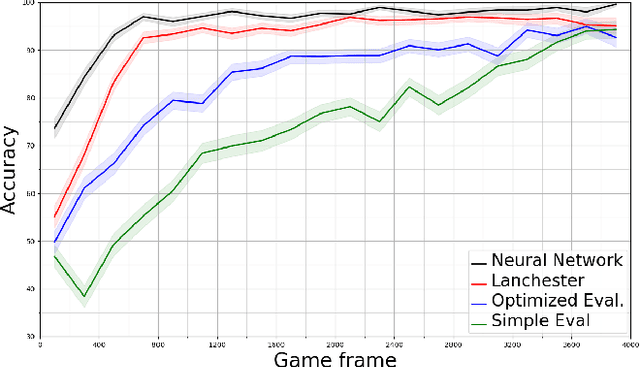
A commonly used technique for managing AI complexity in real-time strategy (RTS) games is to use action and/or state abstractions. High-level abstractions can often lead to good strategic decision making, but tactical decision quality may suffer due to lost details. A competing method is to sample the search space which often leads to good tactical performance in simple scenarios, but poor high-level planning. We propose to use a deep convolutional neural network (CNN) to select among a limited set of abstract action choices, and to utilize the remaining computation time for game tree search to improve low level tactics. The CNN is trained by supervised learning on game states labelled by Puppet Search, a strategic search algorithm that uses action abstractions. The network is then used to select a script --- an abstract action --- to produce low level actions for all units. Subsequently, the game tree search algorithm improves the tactical actions of a subset of units using a limited view of the game state only considering units close to opponent units. Experiments in the microRTS game show that the combined algorithm results in higher win-rates than either of its two independent components and other state-of-the-art microRTS agents. To the best of our knowledge, this is the first successful application of a convolutional network to play a full RTS game on standard game maps, as previous work has focused on sub-problems, such as combat, or on very small maps.
Single-Agent On-line Path Planning in Continuous, Unpredictable and Highly Dynamic Environments
Dec 01, 2009
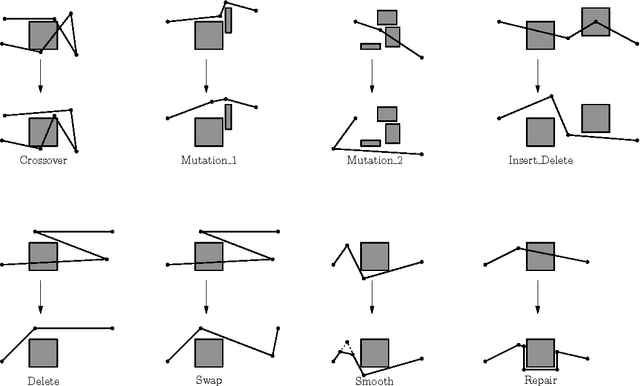
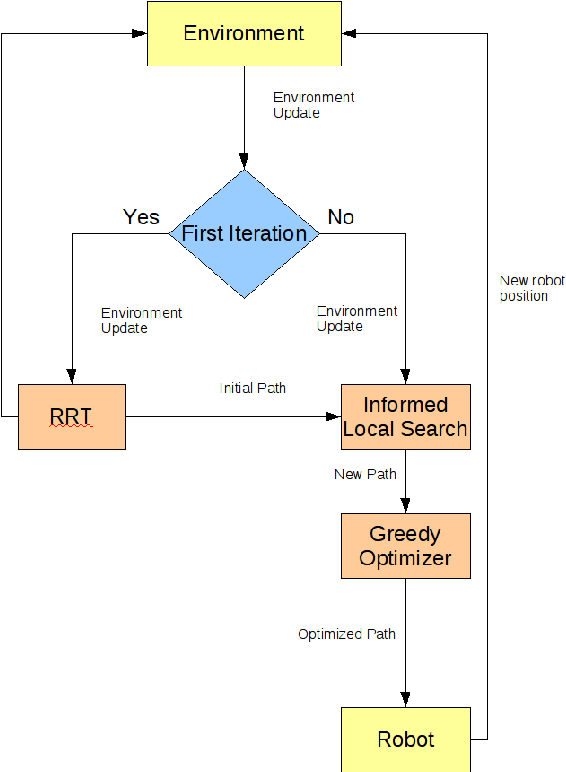
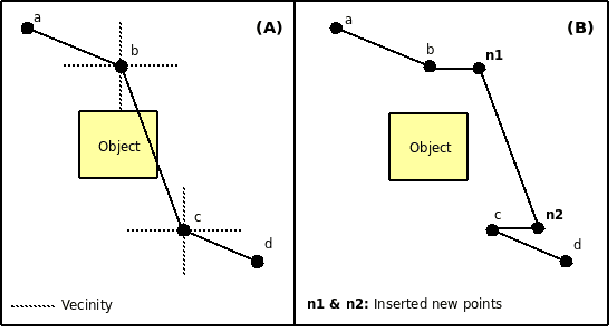
This document is a thesis on the subject of single-agent on-line path planning in continuous,unpredictable and highly dynamic environments. The problem is finding and traversing a collision-free path for a holonomic robot, without kinodynamic restrictions, moving in an environment with several unpredictably moving obstacles or adversaries. The availability of perfect information of the environment at all times is assumed. Several static and dynamic variants of the Rapidly Exploring Random Trees (RRT) algorithm are explored, as well as an evolutionary algorithm for planning in dynamic environments called the Evolutionary Planner/Navigator. A combination of both kinds of algorithms is proposed to overcome shortcomings in both, and then a combination of a RRT variant for initial planning and informed local search for navigation, plus a simple greedy heuristic for optimization. We show that this combination of simple techniques provides better responses to highly dynamic environments than the RRT extensions.
Combining a Probabilistic Sampling Technique and Simple Heuristics to solve the Dynamic Path Planning Problem
Dec 01, 2009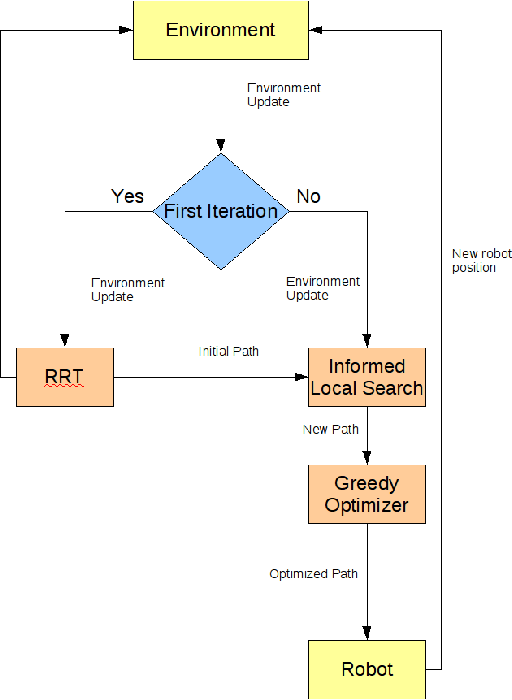
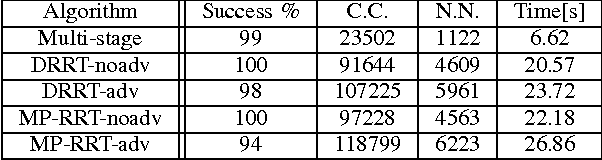
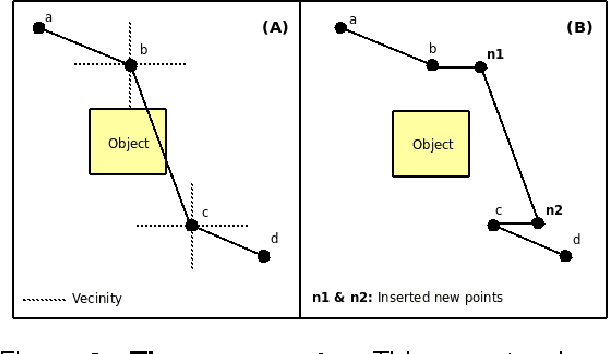
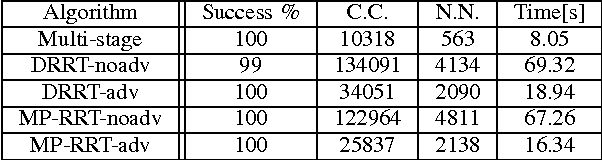
Probabilistic sampling methods have become very popular to solve single-shot path planning problems. Rapidly-exploring Random Trees (RRTs) in particular have been shown to be very efficient in solving high dimensional problems. Even though several RRT variants have been proposed to tackle the dynamic replanning problem, these methods only perform well in environments with infrequent changes. This paper addresses the dynamic path planning problem by combining simple techniques in a multi-stage probabilistic algorithm. This algorithm uses RRTs as an initial solution, informed local search to fix unfeasible paths and a simple greedy optimizer. The algorithm is capable of recognizing when the local search is stuck, and subsequently restart the RRT. We show that this combination of simple techniques provides better responses to a highly dynamic environment than the dynamic RRT variants.
A Multi-stage Probabilistic Algorithm for Dynamic Path-Planning
Dec 01, 2009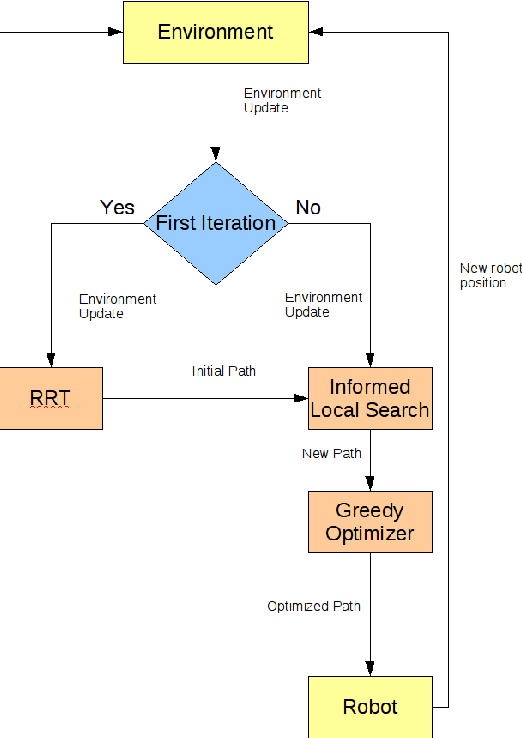
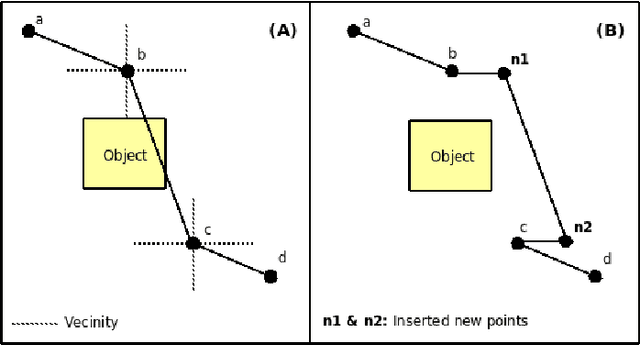
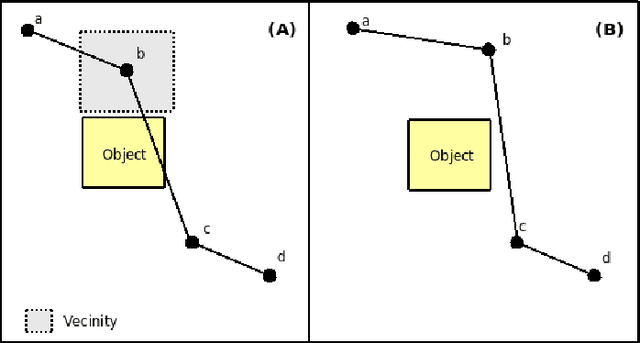
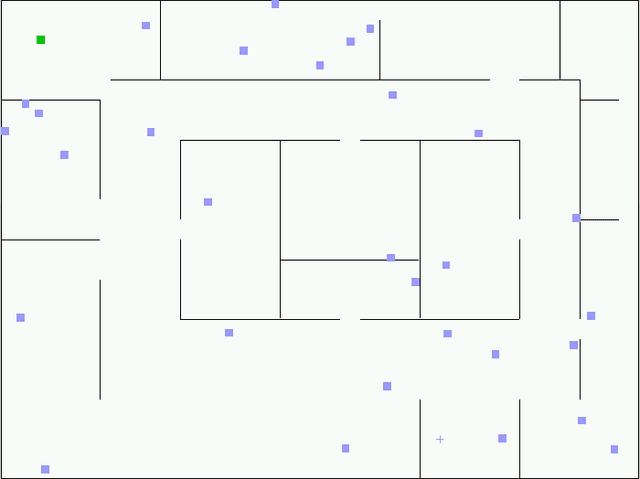
Probabilistic sampling methods have become very popular to solve single-shot path planning problems. Rapidly-exploring Random Trees (RRTs) in particular have been shown to be efficient in solving high dimensional problems. Even though several RRT variants have been proposed for dynamic replanning, these methods only perform well in environments with infrequent changes. This paper addresses the dynamic path planning problem by combining simple techniques in a multi-stage probabilistic algorithm. This algorithm uses RRTs for initial planning and informed local search for navigation. We show that this combination of simple techniques provides better responses to highly dynamic environments than the RRT extensions.