 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting machine failures from multivariate time series: an industrial case study
Feb 27, 2024Non-neural Machine Learning (ML) and Deep Learning (DL) models are often used to predict system failures in the context of industrial maintenance. However, only a few researches jointly assess the effect of varying the amount of past data used to make a prediction and the extension in the future of the forecast. This study evaluates the impact of the size of the reading window and of the prediction window on the performances of models trained to forecast failures in three data sets concerning the operation of (1) an industrial wrapping machine working in discrete sessions, (2) an industrial blood refrigerator working continuously, and (3) a nitrogen generator working continuously. The problem is formulated as a binary classification task that assigns the positive label to the prediction window based on the probability of a failure to occur in such an interval. Six algorithms (logistic regression, random forest, support vector machine, LSTM, ConvLSTM, and Transformers) are compared using multivariate telemetry time series. The results indicate that, in the considered scenarios, the dimension of the prediction windows plays a crucial role and highlight the effectiveness of DL approaches at classifying data with diverse time-dependent patterns preceding a failure and the effectiveness of ML approaches at classifying similar and repetitive patterns preceding a failure.
Time Series Analysis in Compressor-Based Machines: A Survey
Feb 27, 2024In both industrial and residential contexts, compressor-based machines, such as refrigerators, HVAC systems, heat pumps and chillers, are essential to fulfil production and consumers' needs. The diffusion of sensors and IoT connectivity supports the development of monitoring systems able to detect and predict faults, identify behavioural shifts and forecast the operational status of machines and of their components. The focus of this paper is to survey the recent research on such tasks as Fault Detection, Fault Prediction, Forecasting and Change Point Detection applied to multivariate time series characterizing the operations of compressor-based machines. Specifically, Fault Detection detects and diagnoses faults, Fault Prediction predicts such occurrences, forecasting anticipates the future value of characteristic variables of machines and Change Point Detection identifies significant variations in the behaviour of the appliances, such as a change in the working regime. We identify and classify the approaches to the above-mentioned tasks, compare the algorithms employed, highlight the gaps in the current status of the art and discuss the most promising future research directions in the field.
DeepGraviLens: a Multi-Modal Architecture for Classifying Gravitational Lensing Data
May 03, 2022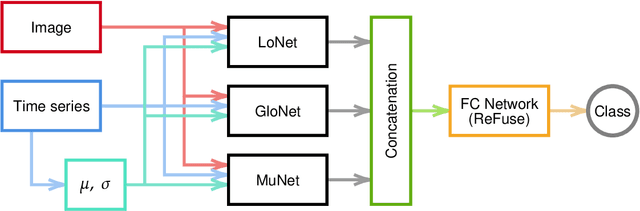
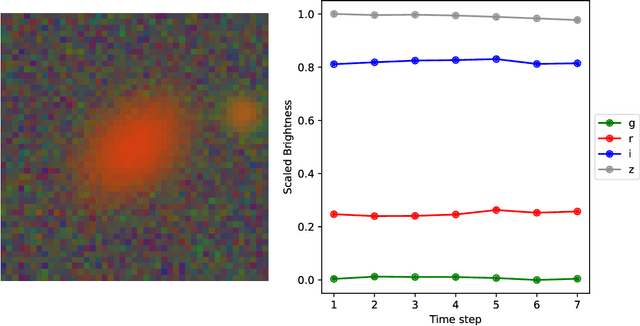
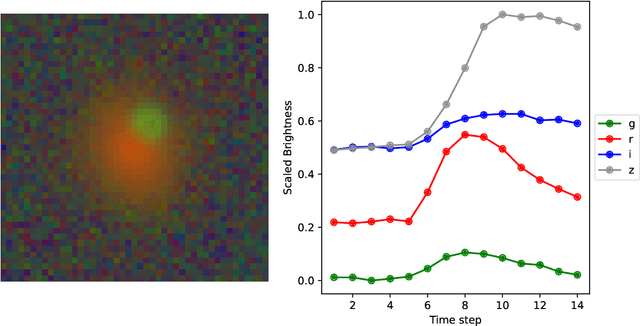
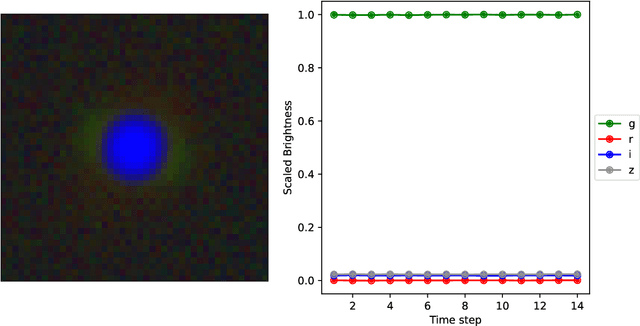
Gravitational lensing is the relativistic effect generated by massive bodies, which bend the space-time surrounding them. It is a deeply investigated topic in astrophysics and allows validating theoretical relativistic results and studying faint astrophysical objects that would not be visible otherwise. In recent years Machine Learning methods have been applied to support the analysis of the gravitational lensing phenomena by detecting lensing effects in data sets consisting of images associated with brightness variation time series. However, the state-of-art approaches either consider only images and neglect time-series data or achieve relatively low accuracy on the most difficult data sets. This paper introduces DeepGraviLens, a novel multi-modal network that classifies spatio-temporal data belonging to one non-lensed system type and three lensed system types. It surpasses the current state of the art accuracy results by $\approx$ 19% to $\approx$ 43%, depending on the considered data set. Such an improvement will enable the acceleration of the analysis of lensed objects in upcoming astrophysical surveys, which will exploit the petabytes of data collected, e.g., from the Vera C. Rubin Observatory.
Using Convolutional Neural Networks for the Helicity Classification of Magnetic Fields
Jun 12, 2021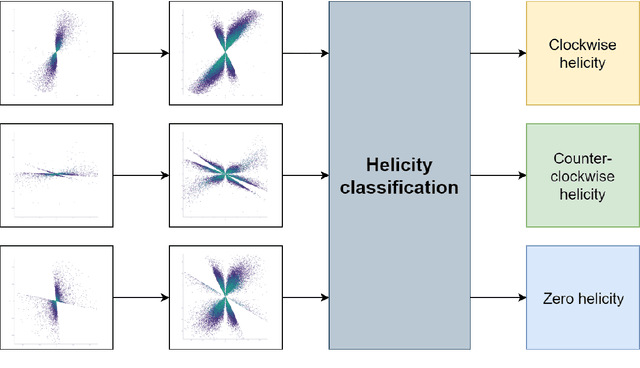
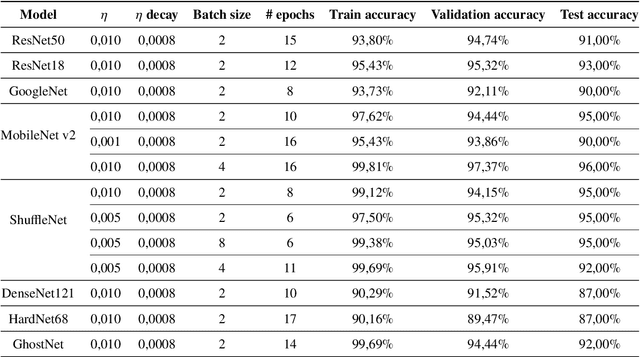
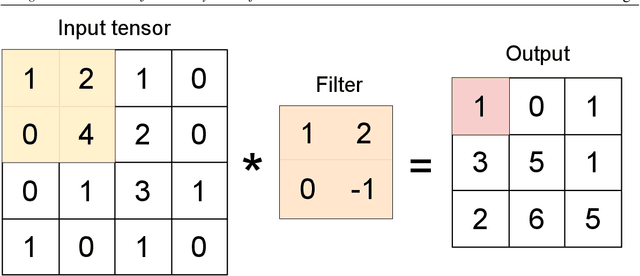
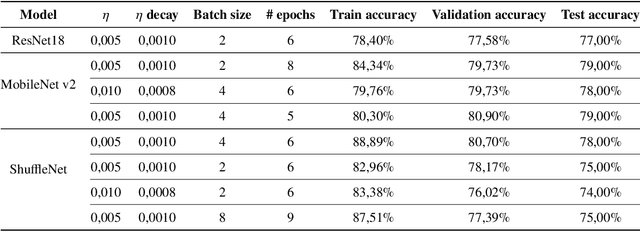
The presence of non-zero helicity in intergalactic magnetic fields is a smoking gun for their primordial origin since they have to be generated by processes that break CP invariance. As an experimental signature for the presence of helical magnetic fields, an estimator $Q$ based on the triple scalar product of the wave-vectors of photons generated in electromagnetic cascades from, e.g., TeV blazars, has been suggested previously. We propose to apply deep learning to helicity classification employing Convolutional Neural Networks and show that this method outperforms the $Q$ estimator.