Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombination of multiple Deep Learning architectures for Offensive Language Detection in Tweets
Mar 25, 2019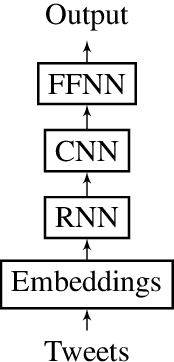
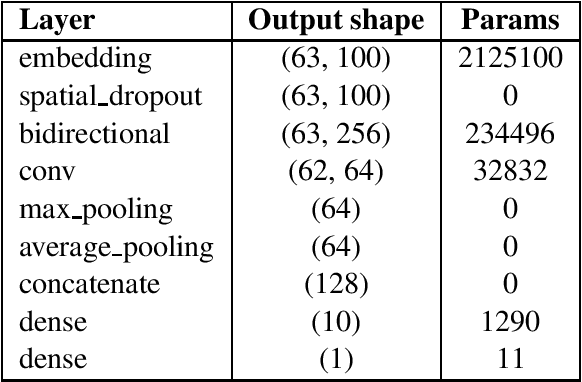
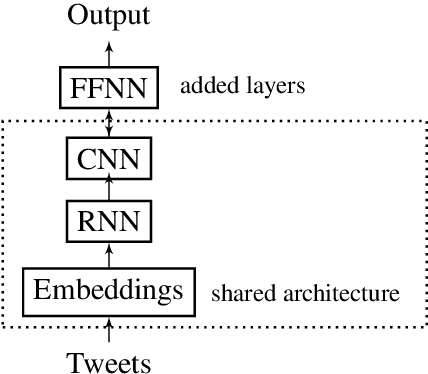
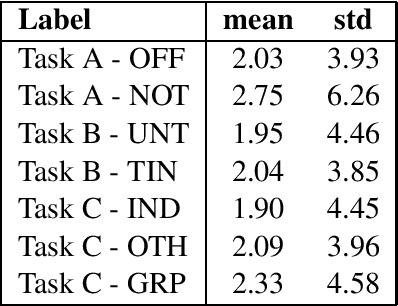
This report contains the details regarding our submission to the OffensEval 2019 (SemEval 2019 - Task 6). The competition was based on the Offensive Language Identification Dataset. We first discuss the details of the classifier implemented and the type of input data used and pre-processing performed. We then move onto critically evaluating our performance. We have achieved a macro-average F1-score of 0.76, 0.68, 0.54, respectively for Task a, Task b, and Task c, which we believe reflects on the level of sophistication of the models implemented. Finally, we will be discussing the difficulties encountered and possible improvements for the future.
Via