 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Global Body Configurations in American Sign Language
Sep 03, 2020



American Sign Language (ASL) is the fourth most commonly used language in the United States and is the language most commonly used by Deaf people in the United States and the English-speaking regions of Canada. Unfortunately, until recently, ASL received little research. This is due, in part, to its delayed recognition as a language until William C. Stokoe's publication in 1960. Limited data has been a long-standing obstacle to ASL research and computational modeling. The lack of large-scale datasets has prohibited many modern machine-learning techniques, such as Neural Machine Translation, from being applied to ASL. In addition, the modality required to capture sign language (i.e. video) is complex in natural settings (as one must deal with background noise, motion blur, and the curse of dimensionality). Finally, when compared with spoken languages, such as English, there has been limited research conducted into the linguistics of ASL. We realize a simplified version of Liddell and Johnson's Movement-Hold (MH) Model using a Probabilistic Graphical Model (PGM). We trained our model on ASLing, a dataset collected from three fluent ASL signers. We evaluate our PGM against other models to determine its ability to model ASL. Finally, we interpret various aspects of the PGM and draw conclusions about ASL phonetics. The main contributions of this paper are
Regression with Uncertainty Quantification in Large Scale Complex Data
Dec 04, 2019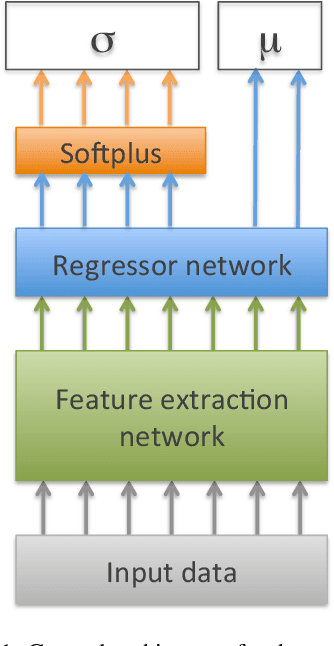
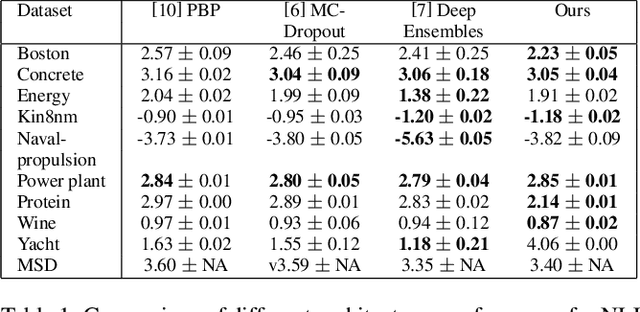


While several methods for predicting uncertainty on deep networks have been recently proposed, they do not readily translate to large and complex datasets. In this paper we utilize a simplified form of the Mixture Density Networks (MDNs) to produce a one-shot approach to quantify uncertainty in regression problems. We show that our uncertainty bounds are on-par or better than other reported existing methods. When applied to standard regression benchmark datasets, we show an improvement in predictive log-likelihood and root-mean-square-error when compared to existing state-of-the-art methods. We also demonstrate this method's efficacy on stochastic, highly volatile time-series data where stock prices are predicted for the next time interval. The resulting uncertainty graph summarizes significant anomalies in the stock price chart. Furthermore, we apply this method to the task of age estimation from the challenging IMDb-Wiki dataset of half a million face images. We successfully predict the uncertainties associated with the prediction and empirically analyze the underlying causes of the uncertainties. This uncertainty quantification can be used to pre-process low quality datasets and further enable learning.