 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNested Named-Entity Recognition on Vietnamese COVID-19: Dataset and Experiments
Apr 21, 2025The COVID-19 pandemic caused great losses worldwide, efforts are taken place to prevent but many countries have failed. In Vietnam, the traceability, localization, and quarantine of people who contact with patients contribute to effective disease prevention. However, this is done by hand, and take a lot of work. In this research, we describe a named-entity recognition (NER) study that assists in the prevention of COVID-19 pandemic in Vietnam. We also present our manually annotated COVID-19 dataset with nested named entity recognition task for Vietnamese which be defined new entity types using for our system.
ViQA-COVID: COVID-19 Machine Reading Comprehension Dataset for Vietnamese
Apr 21, 2025After two years of appearance, COVID-19 has negatively affected people and normal life around the world. As in May 2022, there are more than 522 million cases and six million deaths worldwide (including nearly ten million cases and over forty-three thousand deaths in Vietnam). Economy and society are both severely affected. The variant of COVID-19, Omicron, has broken disease prevention measures of countries and rapidly increased number of infections. Resources overloading in treatment and epidemics prevention is happening all over the world. It can be seen that, application of artificial intelligence (AI) to support people at this time is extremely necessary. There have been many studies applying AI to prevent COVID-19 which are extremely useful, and studies on machine reading comprehension (MRC) are also in it. Realizing that, we created the first MRC dataset about COVID-19 for Vietnamese: ViQA-COVID and can be used to build models and systems, contributing to disease prevention. Besides, ViQA-COVID is also the first multi-span extraction MRC dataset for Vietnamese, we hope that it can contribute to promoting MRC studies in Vietnamese and multilingual.
MAGNeto: An Efficient Deep Learning Method for the Extractive Tags Summarization Problem
Nov 09, 2020

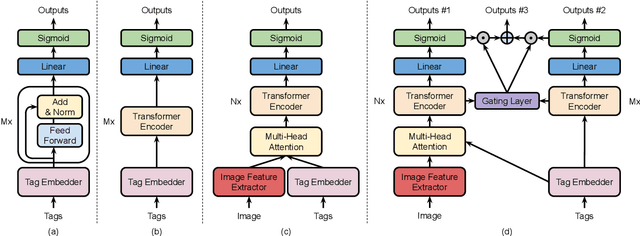

In this work, we study a new image annotation task named Extractive Tags Summarization (ETS). The goal is to extract important tags from the context lying in an image and its corresponding tags. We adjust some state-of-the-art deep learning models to utilize both visual and textual information. Our proposed solution consists of different widely used blocks like convolutional and self-attention layers, together with a novel idea of combining auxiliary loss functions and the gating mechanism to glue and elevate these fundamental components and form a unified architecture. Besides, we introduce a loss function that aims to reduce the imbalance of the training data and a simple but effective data augmentation technique dedicated to alleviates the effect of outliers on the final results. Last but not least, we explore an unsupervised pre-training strategy to further boost the performance of the model by making use of the abundant amount of available unlabeled data. Our model shows the good results as 90% $F_\text{1}$ score on the public NUS-WIDE benchmark, and 50% $F_\text{1}$ score on a noisy large-scale real-world private dataset. Source code for reproducing the experiments is publicly available at: https://github.com/pixta-dev/labteam
On the Vietnamese Name Entity Recognition: A Deep Learning Method Approach
Nov 18, 2019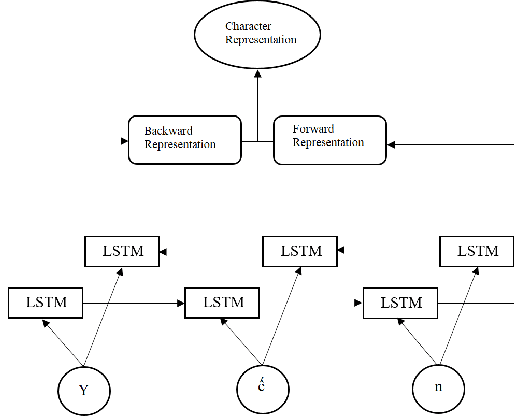
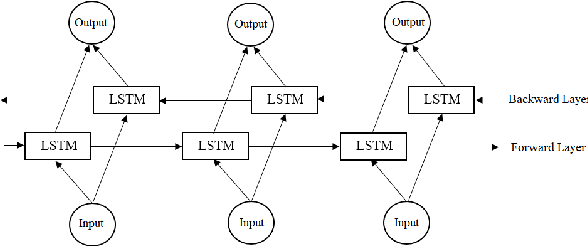
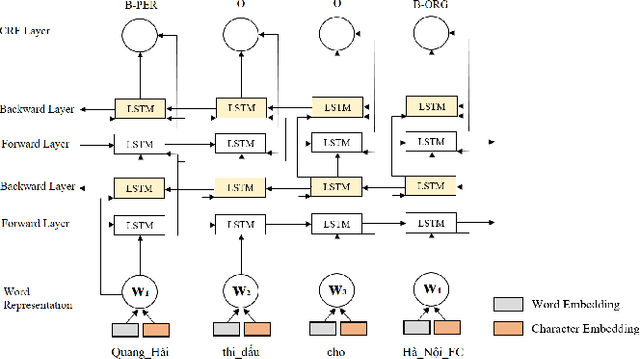

Named entity recognition (NER) plays an important role in text-based information retrieval. In this paper, we combine Bidirectional Long Short-Term Memory (Bi-LSTM) \cite{hochreiter1997,schuster1997} with Conditional Random Field (CRF) \cite{lafferty2001} to create a novel deep learning model for the NER problem. Each word as input of the deep learning model is represented by a Word2vec-trained vector. A word embedding set trained from about one million articles in 2018 collected through a Vietnamese news portal (baomoi.com). In addition, we concatenate a Word2Vec\cite{mikolov2013}-trained vector with semantic feature vector (Part-Of-Speech (POS) tagging, chunk-tag) and hidden syntactic feature vector (extracted by Bi-LSTM nerwork) to achieve the (so far best) result in Vietnamese NER system. The result was conducted on the data set VLSP2016 (Vietnamese Language and Speech Processing 2016 \cite{vlsp2016}) competition.