 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJavaBERT: Training a transformer-based model for the Java programming language
Oct 20, 2021
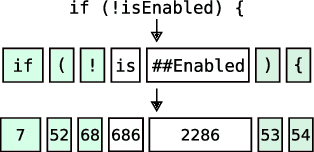
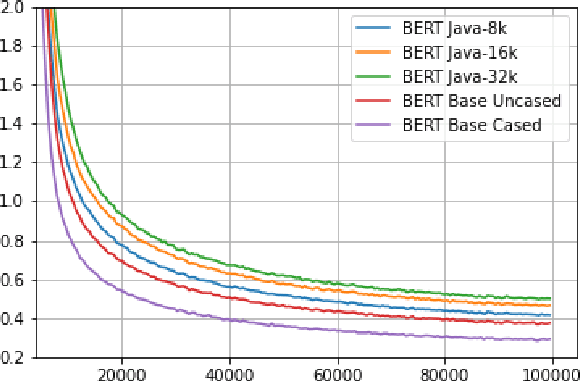

Code quality is and will be a crucial factor while developing new software code, requiring appropriate tools to ensure functional and reliable code. Machine learning techniques are still rarely used for software engineering tools, missing out the potential benefits of its application. Natural language processing has shown the potential to process text data regarding a variety of tasks. We argue, that such models can also show similar benefits for software code processing. In this paper, we investigate how models used for natural language processing can be trained upon software code. We introduce a data retrieval pipeline for software code and train a model upon Java software code. The resulting model, JavaBERT, shows a high accuracy on the masked language modeling task showing its potential for software engineering tools.
Using Supervised Learning to Classify Metadata of Research Data by Discipline of Research
Oct 16, 2019

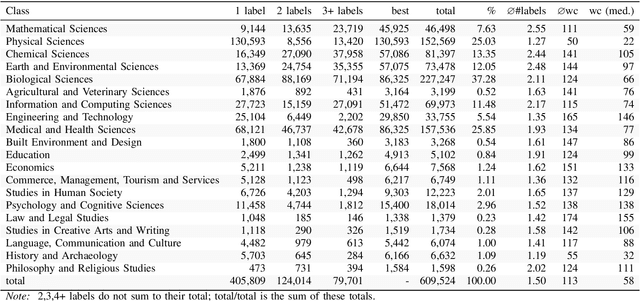
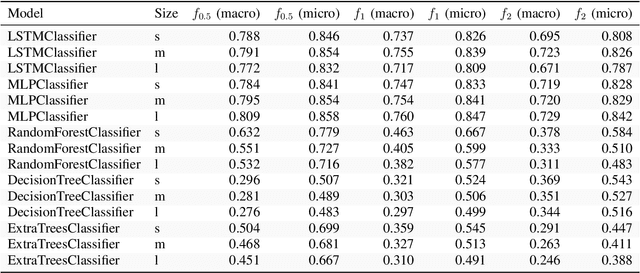
Automated classification of metadata of research data by their discipline(s) of research can be used in scientometric research, by repository service providers, and in the context of research data aggregation services. Openly available metadata of the DataCite index for research data were used to compile a large training and evaluation set comprised of 609,524 records, which is published alongside this paper. These data allow to reproducibly assess classification approaches, such as tree-based models and neural networks. According to our experiments with 20 base classes (multi-label classification), multi-layer perceptron models perform best with a f1-macro score of 0.760 closely followed by Long Short-Term Memory models (f1-macro score of 0.755). A possible application of the trained classification models is the quantitative analysis of trends towards interdisciplinarity of digital scholarly output or the characterization of growth patterns of research data, stratified by discipline of research. Both applications perform at scale with the proposed models which are available for re-use.