 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning for Neural Machine Translation
Dec 30, 2022The machine translation mechanism translates texts automatically between different natural languages, and Neural Machine Translation (NMT) has gained attention for its rational context analysis and fluent translation accuracy. However, processing low-resource languages that lack relevant training attributes like supervised data is a current challenge for Natural Language Processing (NLP). We incorporated a technique known Active Learning with the NMT toolkit Joey NMT to reach sufficient accuracy and robust predictions of low-resource language translation. With active learning, a semi-supervised machine learning strategy, the training algorithm determines which unlabeled data would be the most beneficial for obtaining labels using selected query techniques. We implemented two model-driven acquisition functions for selecting the samples to be validated. This work uses transformer-based NMT systems; baseline model (BM), fully trained model (FTM) , active learning least confidence based model (ALLCM), and active learning margin sampling based model (ALMSM) when translating English to Hindi. The Bilingual Evaluation Understudy (BLEU) metric has been used to evaluate system results. The BLEU scores of BM, FTM, ALLCM and ALMSM systems are 16.26, 22.56 , 24.54, and 24.20, respectively. The findings in this paper demonstrate that active learning techniques helps the model to converge early and improve the overall quality of the translation system.
SARS-CoV-2 Result Interpretation based on Image Analysis of Lateral Flow Devices
May 26, 2022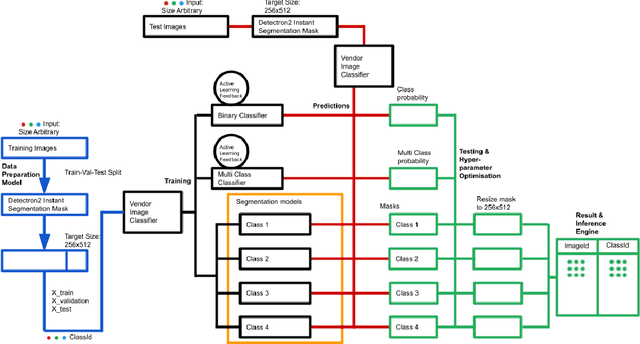


The widely used gene quantisation technique, Lateral Flow Device (LFD), is now commonly used to detect the presence of SARS-CoV-2. It is enabling the control and prevention of the spread of the virus. Depending on the viral load, LFD have different sensitivity and self-test for normal user present additional challenge to interpret the result. With the evolution of machine learning algorithms, image processing and analysis has seen unprecedented growth. In this interdisciplinary study, we employ novel image analysis methods of computer vision and machine learning field to study visual features of the control region of LFD. Here, we automatically derive results for any image containing LFD into positive, negative or inconclusive. This will reduce the burden of human involvement of health workers and perception bias.
An Online Multilingual Hate speech Recognition System
Dec 22, 2020
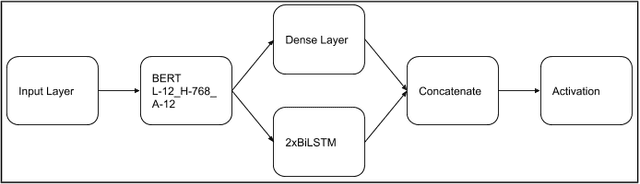

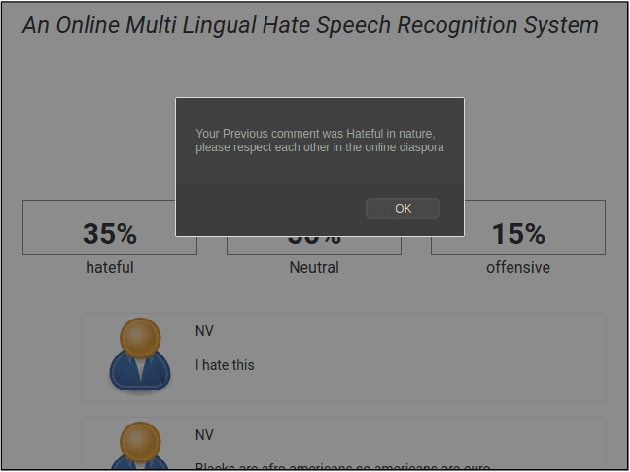
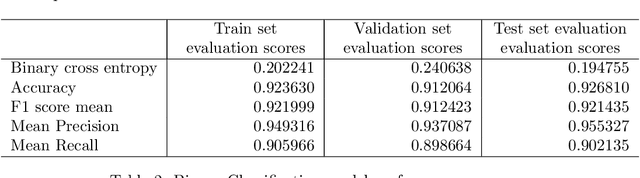
The exponential increase in the use of the Internet and social media over the last two decades has changed human interaction. This has led to many positive outcomes, but at the same time it has brought risks and harms. While the volume of harmful content online, such as hate speech, is not manageable by humans, interest in the academic community to investigate automated means for hate speech detection has increased. In this study, we analyse six publicly available datasets by combining them into a single homogeneous dataset and classify them into three classes, abusive, hateful or neither. We create a baseline model and we improve model performance scores using various optimisation techniques. After attaining a competitive performance score, we create a tool which identifies and scores a page with effective metric in near-real time and uses the same as feedback to re-train our model. We prove the competitive performance of our multilingual model on two langauges, English and Hindi, leading to comparable or superior performance to most monolingual models.
* 11 pages, 5 figures, appear in Special Issue "Natural Language Processing for Social Media" on MDPI Information 2021, 12(1), 5