 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat's Race Got to do with it? Predicting Youth Depression Across Racial Groups Using Machine and Deep Learning
Aug 21, 2023Depression is a common yet serious mental disorder that affects millions of U.S. high schoolers every year. Still, accurate diagnosis and early detection remain significant challenges. In the field of public health, research shows that neural networks produce promising results in identifying other diseases such as cancer and HIV. This study proposes a similar approach, utilizing machine learning (ML) and artificial neural network (ANN) models to classify depression in a student. Additionally, the study highlights the differences in relevant factors for race subgroups and advocates the need for more extensive and diverse datasets. The models train on nationwide Youth Risk Behavior Surveillance System (YRBSS) survey data, in which the most relevant factors of depression are found with statistical analysis. The survey data is a structured dataset with 15000 entries including three race subsets each consisting of 900 entries. For classification, the research problem is modeled as a supervised learning binary classification problem. Factors relevant to depression for different racial subgroups are also identified. The ML and ANN models are trained on the entire dataset followed by different race subsets to classify whether an individual has depression. The ANN model achieves the highest F1 score of 82.90% while the best-performing machine learning model, support vector machines (SVM), achieves a score of 81.90%. This study reveals that different parameters are more valuable for modeling depression across diverse racial groups and furthers research regarding American youth depression.
Transfer Learning with Semi-Supervised Dataset Annotation for Birdcall Classification
Jun 29, 2023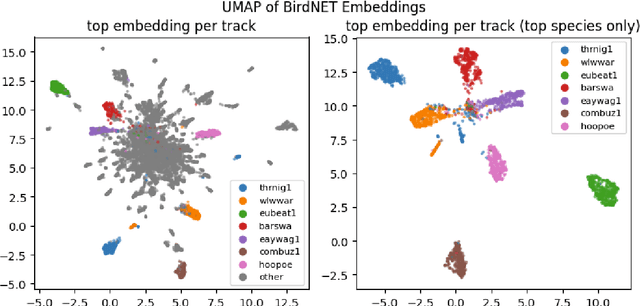

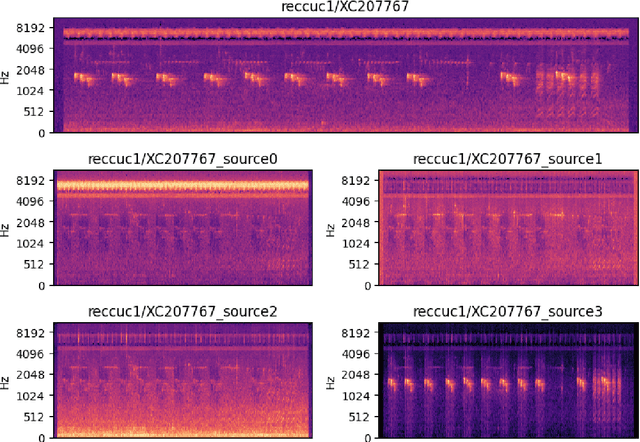

We present working notes on transfer learning with semi-supervised dataset annotation for the BirdCLEF 2023 competition, focused on identifying African bird species in recorded soundscapes. Our approach utilizes existing off-the-shelf models, BirdNET and MixIT, to address representation and labeling challenges in the competition. We explore the embedding space learned by BirdNET and propose a process to derive an annotated dataset for supervised learning. Our experiments involve various models and feature engineering approaches to maximize performance on the competition leaderboard. The results demonstrate the effectiveness of our approach in classifying bird species and highlight the potential of transfer learning and semi-supervised dataset annotation in similar tasks.