 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Continuously Differentiable Activation Functions for Learning in Quantized Noisy Environments
Feb 04, 2024

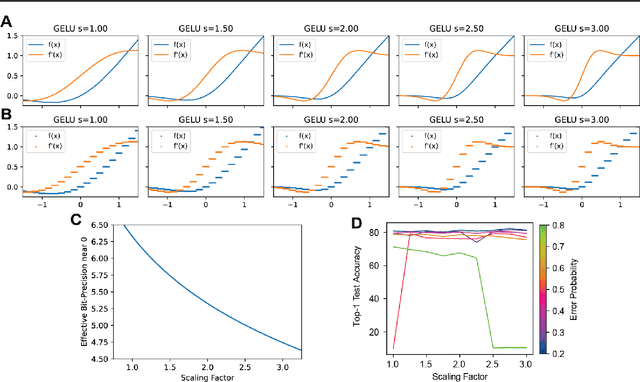

Real-world analog systems intrinsically suffer from noise that can impede model convergence and accuracy on a variety of deep learning models. We demonstrate that differentiable activations like GELU and SiLU enable robust propagation of gradients which help to mitigate analog quantization error that is ubiquitous to all analog systems. We perform analysis and training of convolutional, linear, and transformer networks in the presence of quantized noise. Here, we are able to demonstrate that continuously differentiable activation functions are significantly more noise resilient over conventional rectified activations. As in the case of ReLU, the error in gradients are 100x higher than those in GELU near zero. Our findings provide guidance for selecting appropriate activations to realize performant and reliable hardware implementations across several machine learning domains such as computer vision, signal processing, and beyond.
AnalogVNN: A fully modular framework for modeling and optimizing photonic neural networks
Oct 14, 2022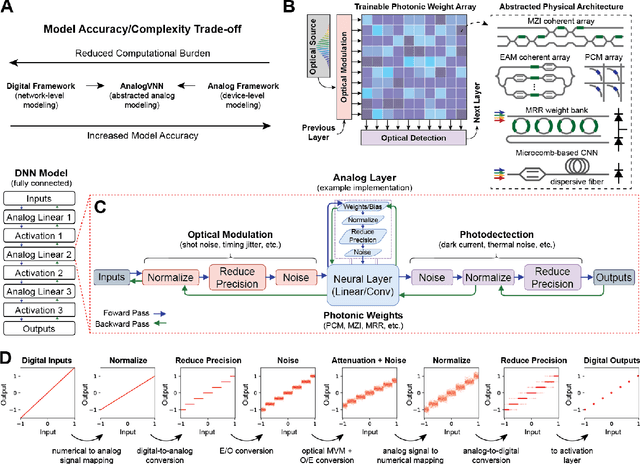
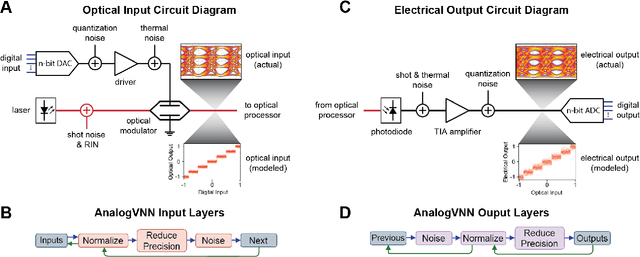


In this paper, we present AnalogVNN, a simulation framework built on PyTorch which can simulate the effects of optoelectronic noise, limited precision, and signal normalization present in photonic neural network accelerators. We use this framework to train and optimize linear and convolutional neural networks with up to 9 layers and ~1.7 million parameters, while gaining insights into how normalization, activation function, reduced precision, and noise influence accuracy in analog photonic neural networks. By following the same layer structure design present in PyTorch, the AnalogVNN framework allows users to convert most digital neural network models to their analog counterparts with just a few lines of code, taking full advantage of the open-source optimization, deep learning, and GPU acceleration libraries available through PyTorch.
Monadic Pavlovian associative learning in a backpropagation-free photonic network
Nov 30, 2020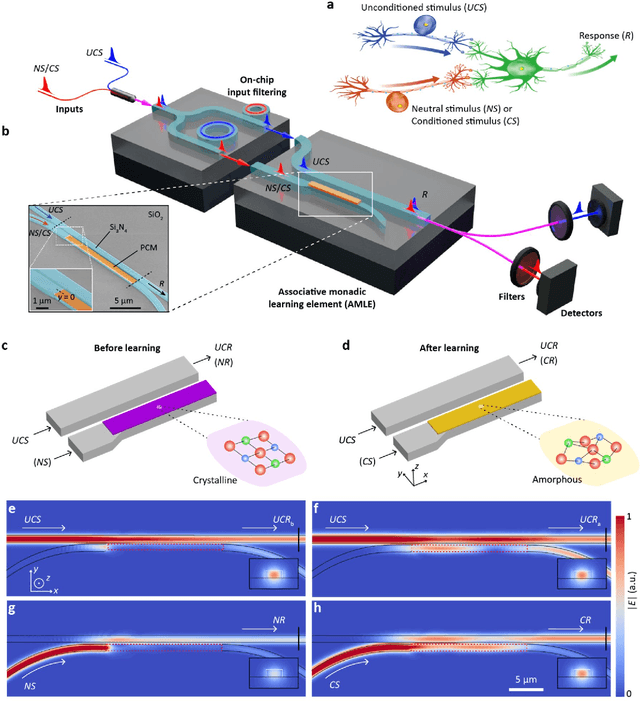
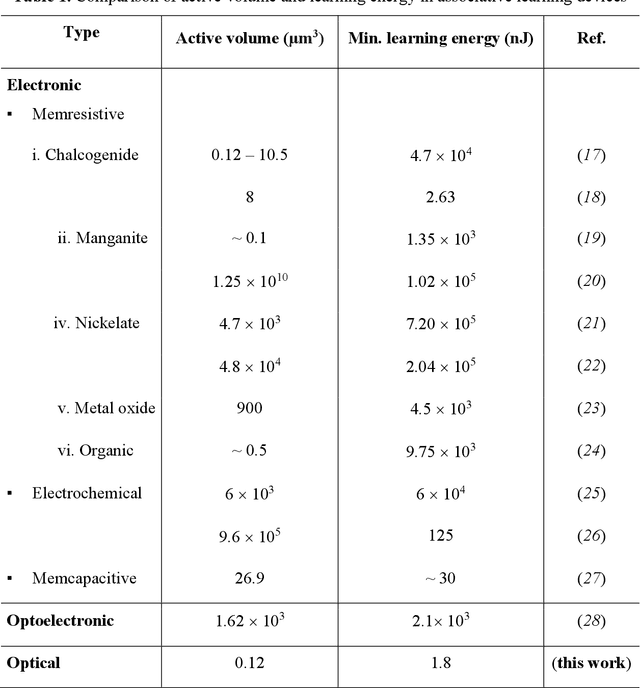
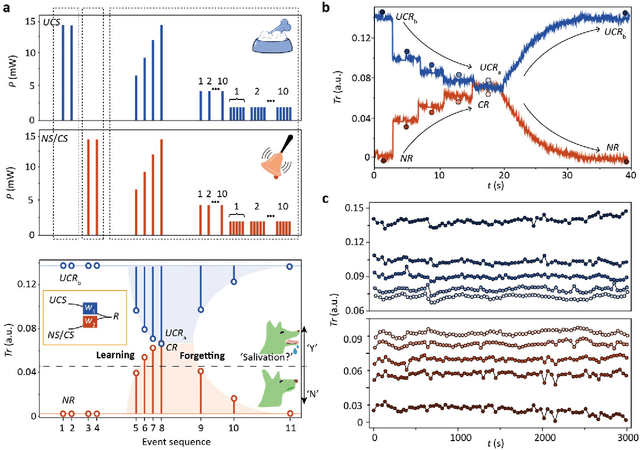
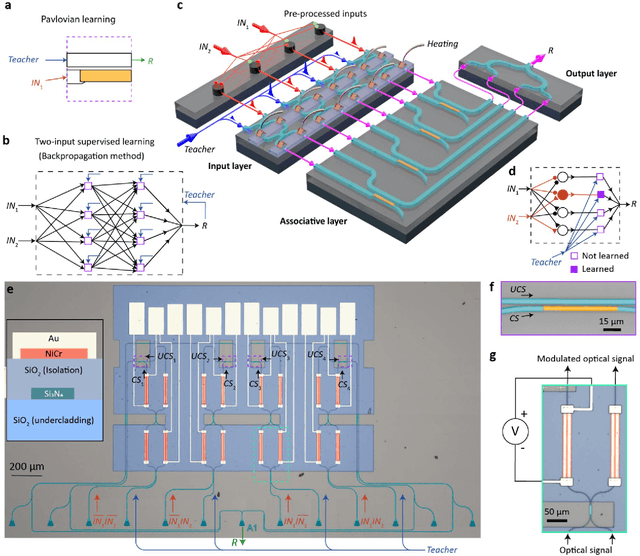
Over a century ago, Ivan P. Pavlov, in a classic experiment, demonstrated how dogs can learn to associate a ringing bell with food, thereby causing a ring to result in salivation. Today, however, it is rare to find the use of Pavlovian type associative learning for artificial intelligence (AI) applications. Instead, other biologically-inspired learning concepts, in particular artificial neural networks (ANNs) have flourished, yielding extensive impact on a wide range of fields including finance, healthcare and transportation. However, learning in such "conventional" ANNs, in particular in the form of modern deep neural networks (DNNs) are usually carried out using the backpropagation method, is computationally and energy intensive. Here we report the experimental demonstration of backpropagation-free learning, achieved using a single (or monadic) associative hardware element. This is realized on an integrated photonic platform using phase change materials combined with on-chip cascaded directional couplers. We link associative learning with supervised learning, based on their common goal of associating certain inputs with "correct" outputs. We then expand the concept to develop larger-scale supervised learning networks using our monadic Pavlovian photonic hardware, developing a distinct machine-learning framework based on single-element associations and, importantly, using backpropagation-free single-layer weight architectures to approach general learning tasks. Our approach not only significantly reduces the computational burden imposed by learning in conventional neural network approaches, thereby increasing speed and decreasing energy use during learning, but also offers higher bandwidth inherent to a photonic implementation, paving the way for future deployment of fast photonic artificially intelligent machines.