 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemote Labor Index: Measuring AI Automation of Remote Work
Oct 30, 2025AIs have made rapid progress on research-oriented benchmarks of knowledge and reasoning, but it remains unclear how these gains translate into economic value and automation. To measure this, we introduce the Remote Labor Index (RLI), a broadly multi-sector benchmark comprising real-world, economically valuable projects designed to evaluate end-to-end agent performance in practical settings. AI agents perform near the floor on RLI, with the highest-performing agent achieving an automation rate of 2.5%. These results help ground discussions of AI automation in empirical evidence, setting a common basis for tracking AI impacts and enabling stakeholders to proactively navigate AI-driven labor automation.
Leveraging Continuously Differentiable Activation Functions for Learning in Quantized Noisy Environments
Feb 04, 2024

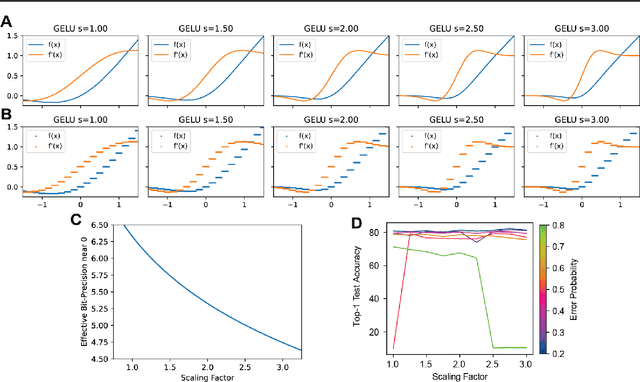

Real-world analog systems intrinsically suffer from noise that can impede model convergence and accuracy on a variety of deep learning models. We demonstrate that differentiable activations like GELU and SiLU enable robust propagation of gradients which help to mitigate analog quantization error that is ubiquitous to all analog systems. We perform analysis and training of convolutional, linear, and transformer networks in the presence of quantized noise. Here, we are able to demonstrate that continuously differentiable activation functions are significantly more noise resilient over conventional rectified activations. As in the case of ReLU, the error in gradients are 100x higher than those in GELU near zero. Our findings provide guidance for selecting appropriate activations to realize performant and reliable hardware implementations across several machine learning domains such as computer vision, signal processing, and beyond.
AnalogVNN: A fully modular framework for modeling and optimizing photonic neural networks
Oct 14, 2022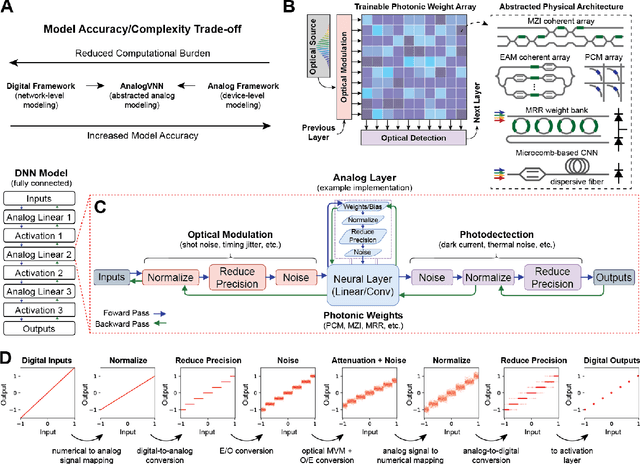
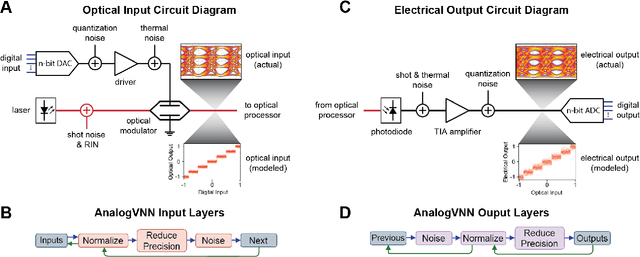


In this paper, we present AnalogVNN, a simulation framework built on PyTorch which can simulate the effects of optoelectronic noise, limited precision, and signal normalization present in photonic neural network accelerators. We use this framework to train and optimize linear and convolutional neural networks with up to 9 layers and ~1.7 million parameters, while gaining insights into how normalization, activation function, reduced precision, and noise influence accuracy in analog photonic neural networks. By following the same layer structure design present in PyTorch, the AnalogVNN framework allows users to convert most digital neural network models to their analog counterparts with just a few lines of code, taking full advantage of the open-source optimization, deep learning, and GPU acceleration libraries available through PyTorch.