 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Mixture of Interpretable Experts for Global and Local Interpretability
Dec 01, 2022



We investigate the feasibility of using mixtures of interpretable experts (MoIE) to build interpretable image classifiers on MNIST10. MoIE uses a black-box router to assign each input to one of many inherently interpretable experts, thereby providing insight into why a particular classification decision was made. We find that a naively trained MoIE will learn to 'cheat', whereby the black-box router will solve the classification problem by itself, with each expert simply learning a constant function for one particular class. We propose to solve this problem by introducing interpretable routers and training the black-box router's decisions to match the interpretable router. In addition, we propose a novel implicit parameterization scheme that allows us to build mixtures of arbitrary numbers of experts, allowing us to study how classification performance, local and global interpretability vary as the number of experts is increased. Our new model, dubbed Implicit Mixture of Interpretable Experts (IMoIE) can match state-of-the-art classification accuracy on MNIST10 while providing local interpretability, and can provide global interpretability albeit at the cost of reduced classification accuracy.
Conditional Autoregressors are Interpretable Classifiers
Mar 31, 2022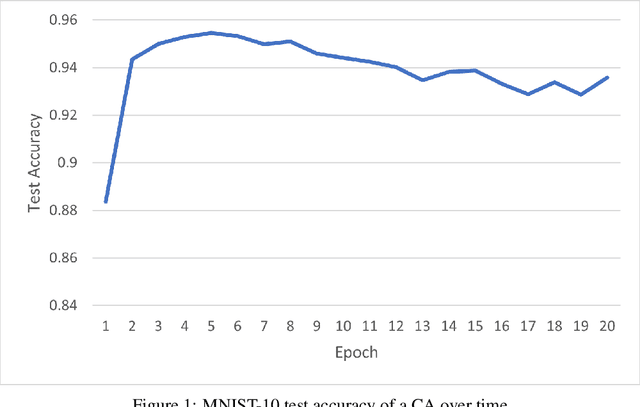
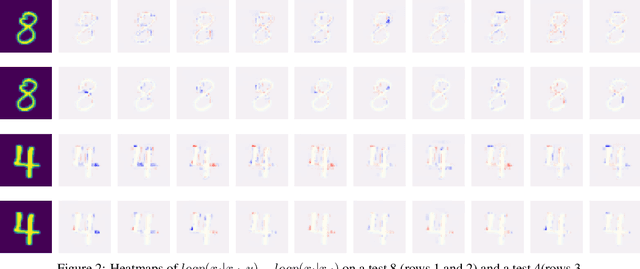
We explore the use of class-conditional autoregressive (CA) models to perform image classification on MNIST-10. Autoregressive models assign probability to an entire input by combining probabilities from each individual feature; hence classification decisions made by a CA can be readily decomposed into contributions from each each input feature. That is to say, CA are inherently locally interpretable. Our experiments show that naively training a CA achieves much worse accuracy compared to a standard classifier, however this is due to over-fitting and not a lack of expressive power. Using knowledge distillation from a standard classifier, a student CA can be trained to match the performance of the teacher while still being interpretable.