Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Autoregressors are Interpretable Classifiers
Paper and Code
Mar 31, 2022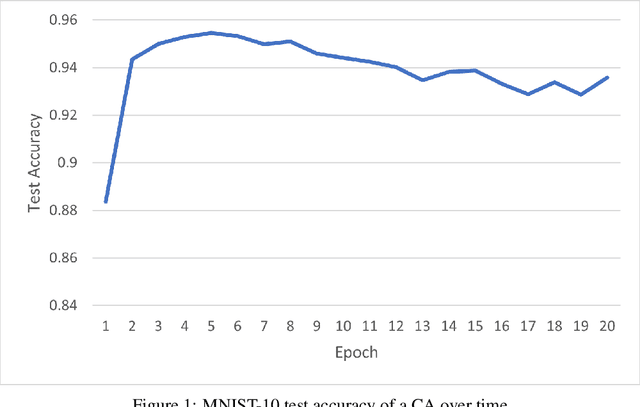
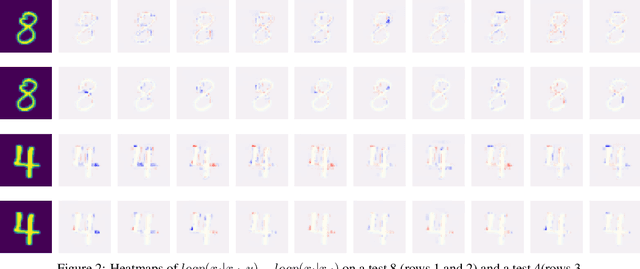
We explore the use of class-conditional autoregressive (CA) models to perform image classification on MNIST-10. Autoregressive models assign probability to an entire input by combining probabilities from each individual feature; hence classification decisions made by a CA can be readily decomposed into contributions from each each input feature. That is to say, CA are inherently locally interpretable. Our experiments show that naively training a CA achieves much worse accuracy compared to a standard classifier, however this is due to over-fitting and not a lack of expressive power. Using knowledge distillation from a standard classifier, a student CA can be trained to match the performance of the teacher while still being interpretable.
* 4 pages, 2 figures
View paper on