 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Radiology Report Generation Systems by Removing Hallucinated References to Non-existent Priors
Sep 27, 2022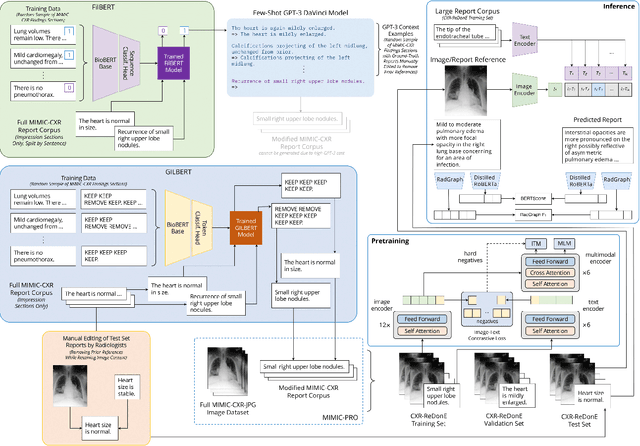

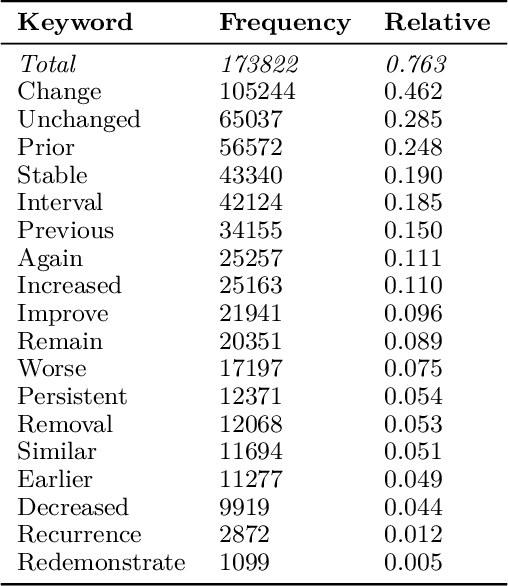

Current deep learning models trained to generate radiology reports from chest radiographs are capable of producing clinically accurate, clear, and actionable text that can advance patient care. However, such systems all succumb to the same problem: making hallucinated references to non-existent prior reports. Such hallucinations occur because these models are trained on datasets of real-world patient reports that inherently refer to priors. To this end, we propose two methods to remove references to priors in radiology reports: (1) a GPT-3-based few-shot approach to rewrite medical reports without references to priors; and (2) a BioBERT-based token classification approach to directly remove words referring to priors. We use the aforementioned approaches to modify MIMIC-CXR, a publicly available dataset of chest X-rays and their associated free-text radiology reports; we then retrain CXR-RePaiR, a radiology report generation system, on the adapted MIMIC-CXR dataset. We find that our re-trained model--which we call CXR-ReDonE--outperforms previous report generation methods on clinical metrics, achieving an average BERTScore of 0.2351 (2.57% absolute improvement). We expect our approach to be broadly valuable in enabling current radiology report generation systems to be more directly integrated into clinical pipelines.