 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiered approach for rapid damage characterisation of infrastructure enabled by remote sensing and deep learning technologies
Feb 01, 2024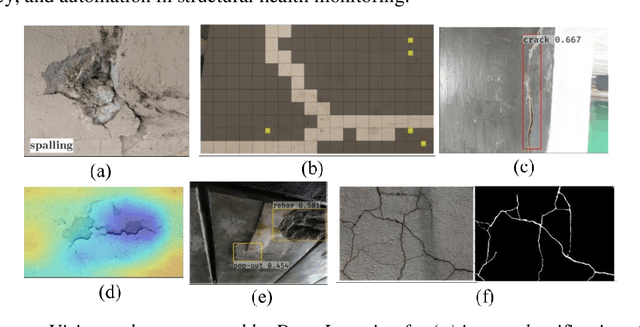
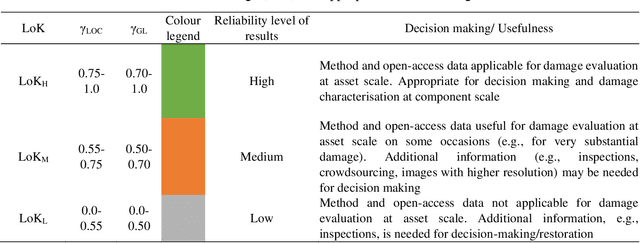
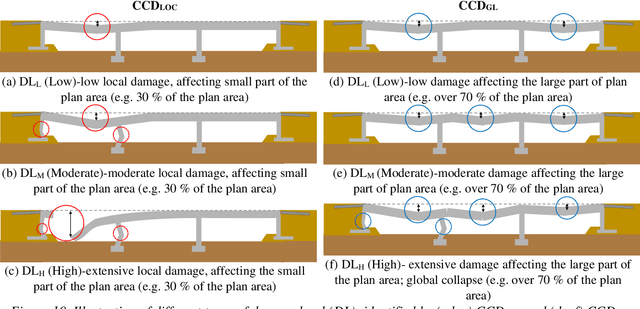
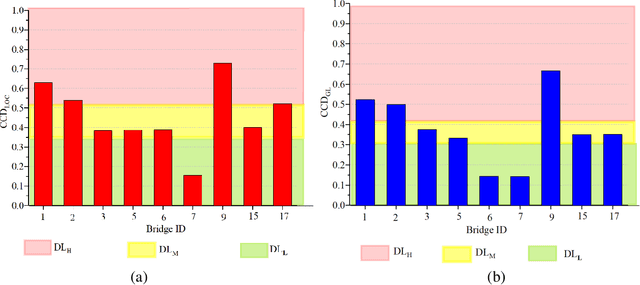
Critical infrastructure such as bridges are systematically targeted during wars and conflicts. This is because critical infrastructure is vital for enabling connectivity and transportation of people and goods, and hence, underpinning the national and international defence planning and economic growth. Mass destruction of bridges, along with minimal or no accessibility to these assets during natural and anthropogenic disasters, prevents us from delivering rapid recovery. As a result, systemic resilience is drastically reduced. A solution to this challenge is to use technology for stand-off observations. Yet, no method exists to characterise damage at different scales, i.e. regional, asset, and structural (component), and more so there is little or no systematic correlation between assessments at scale. We propose an integrated three-level tiered approach to fill this capability gap, and we demonstrate the methods for damage characterisation enabled by fit-for-purpose digital technologies. Next, this method is applied and validated to a case study in Ukraine that includes 17 bridges. From macro to micro, we deploy technology at scale, from Sentinel-1 SAR images, crowdsourced information, and high-resolution images to deep learning for damaged infrastructure. For the first time, the interferometric coherence difference and semantic segmentation of images were deployed to improve the reliability of damage characterisations from regional to infrastructure component level, when enhanced assessment accuracy is required. This integrated method improves the speed of decision-making, and thus, enhances resilience. Keywords: critical infrastructure, damage characterisation, targeted attacks, restoration
The method of automatic summarization from different sources
May 04, 2019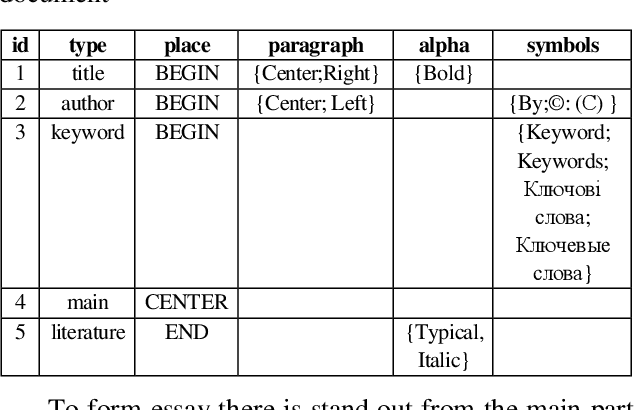
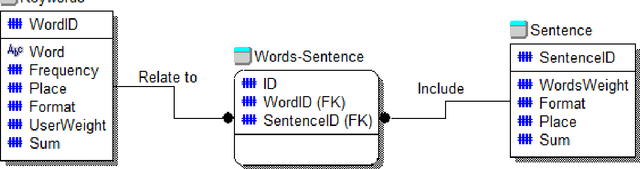
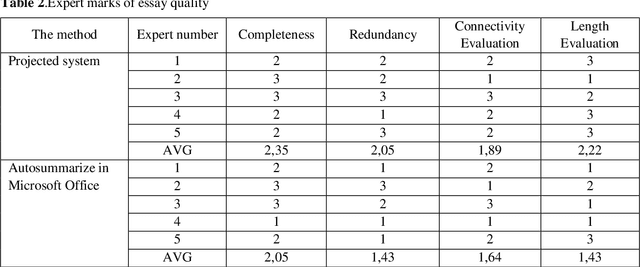
In this article is analyzed technology of automatic text abstracting and annotation. The role of annotation in automatic search and classification for different scientific articles is described. The algorithm of summarization of natural language documents using the concept of importance coefficients is developed. Such concept allows considering the peculiarity of subject areas and topics that could be found in different kinds of documents. Method for generating abstracts of single document based on frequency analysis is developed. The recognition elements for unstructured text analysis are given. The method of pre-processing analysis of several documents is developed. This technique simultaneously considers both statistical approaches to abstracting and the importance of terms in a particular subject domain. The quality of generated abstract is evaluated. For the developed system there was conducted experts evaluation. It was held only for texts in Ukrainian. The developed system concluding essay has higher aggregate score on all criteria. The summarization system architecture is building. To build an information system model there is used CASE-tool AllFusion ERwin Data Modeler. The database scheme for information saving was built. The system is designed to work primarily with Ukrainian texts, which gives a significant advantage, since most modern systems still oriented to English texts