 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe method of automatic summarization from different sources
Paper and Code
May 04, 2019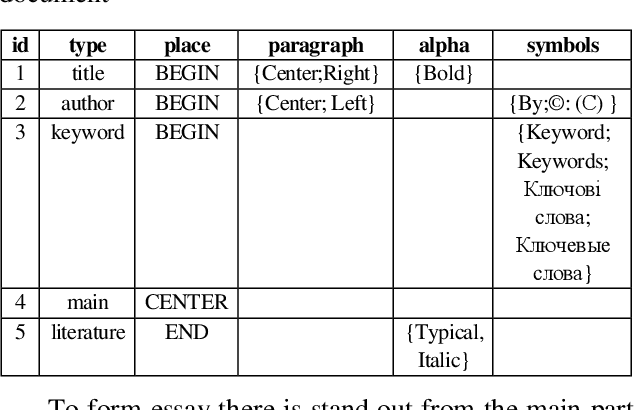
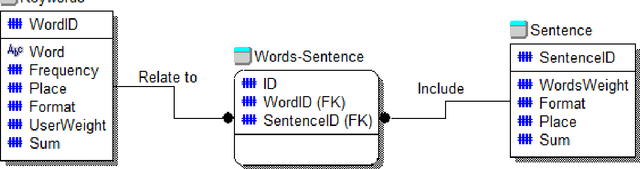
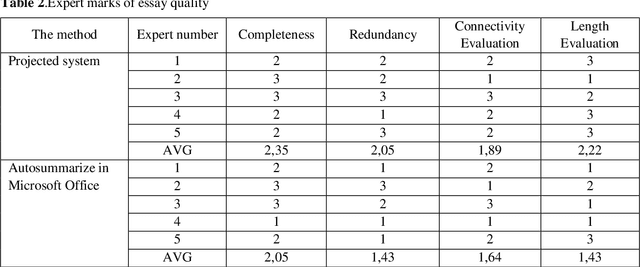
In this article is analyzed technology of automatic text abstracting and annotation. The role of annotation in automatic search and classification for different scientific articles is described. The algorithm of summarization of natural language documents using the concept of importance coefficients is developed. Such concept allows considering the peculiarity of subject areas and topics that could be found in different kinds of documents. Method for generating abstracts of single document based on frequency analysis is developed. The recognition elements for unstructured text analysis are given. The method of pre-processing analysis of several documents is developed. This technique simultaneously considers both statistical approaches to abstracting and the importance of terms in a particular subject domain. The quality of generated abstract is evaluated. For the developed system there was conducted experts evaluation. It was held only for texts in Ukrainian. The developed system concluding essay has higher aggregate score on all criteria. The summarization system architecture is building. To build an information system model there is used CASE-tool AllFusion ERwin Data Modeler. The database scheme for information saving was built. The system is designed to work primarily with Ukrainian texts, which gives a significant advantage, since most modern systems still oriented to English texts