 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Mining using Nonnegative Matrix Factorization and Latent Semantic Analysis
Nov 12, 2019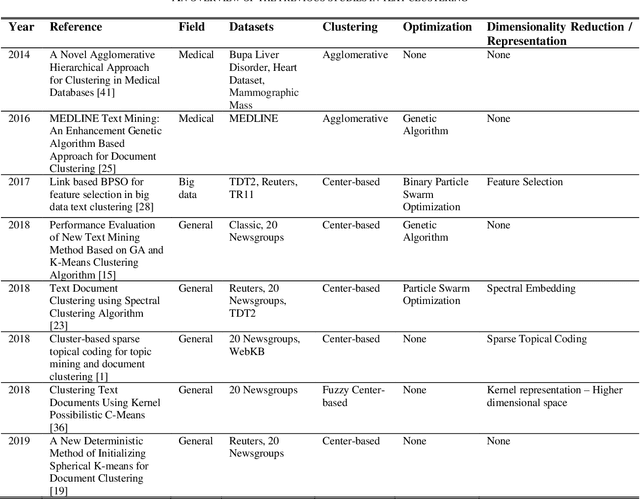
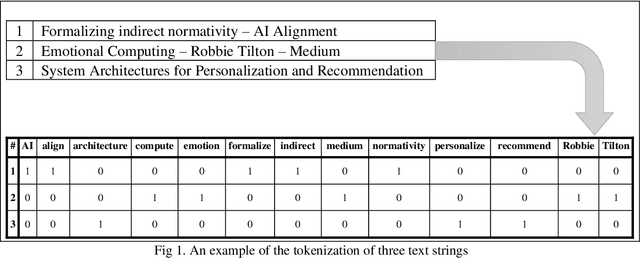

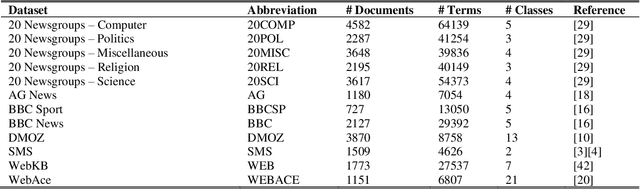
Text clustering is arguably one of the most important topics in modern data mining. Nevertheless, text data require tokenization which usually yields a very large and highly sparse term-document matrix, which is usually difficult to process using conventional machine learning algorithms. Methods such as Latent Semantic Analysis have helped mitigate this issue, but are nevertheless not completely stable in practice. As a result, we propose a new feature agglomeration method based on Nonnegative Matrix Factorization. NMF is employed to separate the terms into groups, and then each group`s term vectors are agglomerated into a new feature vector. Together, these feature vectors create a new feature space much more suitable for clustering. In addition, we propose a new deterministic initialization for spherical K-Means, which proves very useful for this specific type of data. In order to evaluate the proposed method, we compare it to some of the latest research done in this field, as well as some of the most practiced methods. In our experiments, we conclude that the proposed method either significantly improves clustering performance, or maintains the performance of other methods, while improving stability in results.