 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Reliable Matching with Phase Enhancement for Night-time Semantic Segmentation
Aug 25, 2024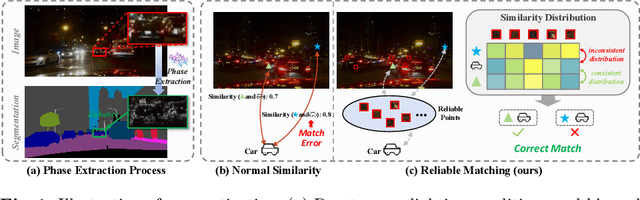

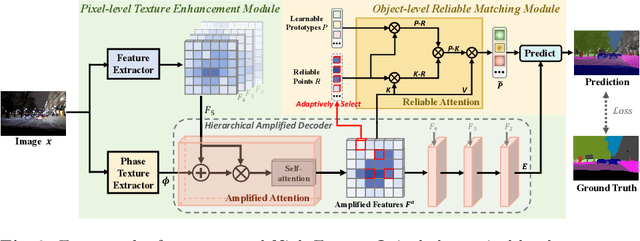
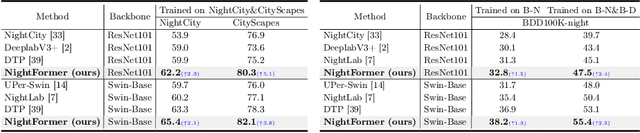
Semantic segmentation of night-time images holds significant importance in computer vision, particularly for applications like night environment perception in autonomous driving systems. However, existing methods tend to parse night-time images from a day-time perspective, leaving the inherent challenges in low-light conditions (such as compromised texture and deceiving matching errors) unexplored. To address these issues, we propose a novel end-to-end optimized approach, named NightFormer, tailored for night-time semantic segmentation, avoiding the conventional practice of forcibly fitting night-time images into day-time distributions. Specifically, we design a pixel-level texture enhancement module to acquire texture-aware features hierarchically with phase enhancement and amplified attention, and an object-level reliable matching module to realize accurate association matching via reliable attention in low-light environments. Extensive experimental results on various challenging benchmarks including NightCity, BDD and Cityscapes demonstrate that our proposed method performs favorably against state-of-the-art night-time semantic segmentation methods.
Image-to-Image Matching via Foundation Models: A New Perspective for Open-Vocabulary Semantic Segmentation
Mar 30, 2024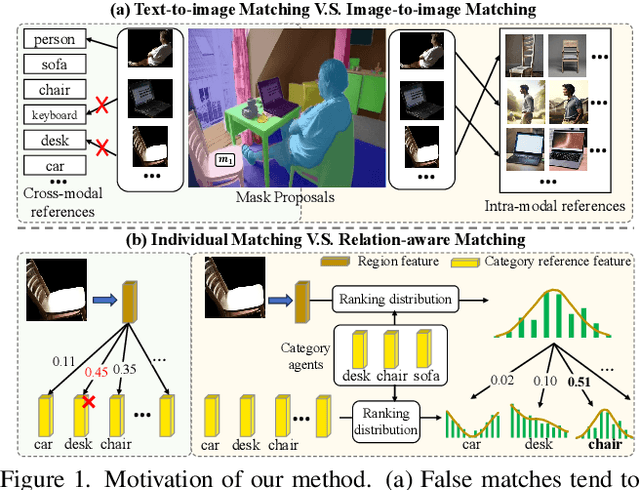



Open-vocabulary semantic segmentation (OVS) aims to segment images of arbitrary categories specified by class labels or captions. However, most previous best-performing methods, whether pixel grouping methods or region recognition methods, suffer from false matches between image features and category labels. We attribute this to the natural gap between the textual features and visual features. In this work, we rethink how to mitigate false matches from the perspective of image-to-image matching and propose a novel relation-aware intra-modal matching (RIM) framework for OVS based on visual foundation models. RIM achieves robust region classification by firstly constructing diverse image-modal reference features and then matching them with region features based on relation-aware ranking distribution. The proposed RIM enjoys several merits. First, the intra-modal reference features are better aligned, circumventing potential ambiguities that may arise in cross-modal matching. Second, the ranking-based matching process harnesses the structure information implicit in the inter-class relationships, making it more robust than comparing individually. Extensive experiments on three benchmarks demonstrate that RIM outperforms previous state-of-the-art methods by large margins, obtaining a lead of more than 10% in mIoU on PASCAL VOC benchmark.
Focus on Query: Adversarial Mining Transformer for Few-Shot Segmentation
Nov 29, 2023Few-shot segmentation (FSS) aims to segment objects of new categories given only a handful of annotated samples. Previous works focus their efforts on exploring the support information while paying less attention to the mining of the critical query branch. In this paper, we rethink the importance of support information and propose a new query-centric FSS model Adversarial Mining Transformer (AMFormer), which achieves accurate query image segmentation with only rough support guidance or even weak support labels. The proposed AMFormer enjoys several merits. First, we design an object mining transformer (G) that can achieve the expansion of incomplete region activated by support clue, and a detail mining transformer (D) to discriminate the detailed local difference between the expanded mask and the ground truth. Second, we propose to train G and D via an adversarial process, where G is optimized to generate more accurate masks approaching ground truth to fool D. We conduct extensive experiments on commonly used Pascal-5i and COCO-20i benchmarks and achieve state-of-the-art results across all settings. In addition, the decent performance with weak support labels in our query-centric paradigm may inspire the development of more general FSS models. Code will be available at https://github.com/Wyxdm/AMNet.