 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBARC: Learning to Regress 3D Dog Shape from Images by Exploiting Breed Information
Mar 30, 2022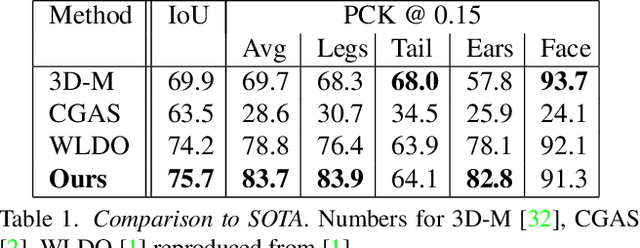
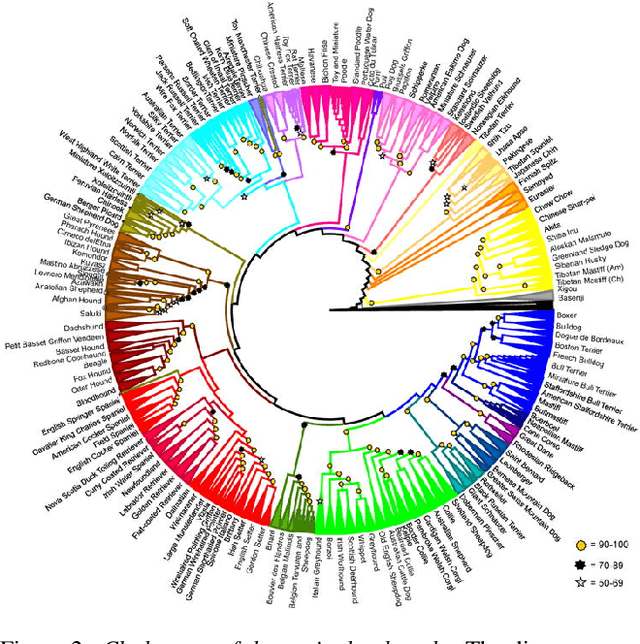

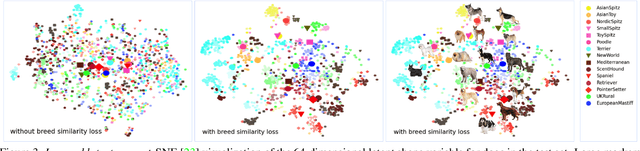
Our goal is to recover the 3D shape and pose of dogs from a single image. This is a challenging task because dogs exhibit a wide range of shapes and appearances, and are highly articulated. Recent work has proposed to directly regress the SMAL animal model, with additional limb scale parameters, from images. Our method, called BARC (Breed-Augmented Regression using Classification), goes beyond prior work in several important ways. First, we modify the SMAL shape space to be more appropriate for representing dog shape. But, even with a better shape model, the problem of regressing dog shape from an image is still challenging because we lack paired images with 3D ground truth. To compensate for the lack of paired data, we formulate novel losses that exploit information about dog breeds. In particular, we exploit the fact that dogs of the same breed have similar body shapes. We formulate a novel breed similarity loss consisting of two parts: One term encourages the shape of dogs from the same breed to be more similar than dogs of different breeds. The second one, a breed classification loss, helps to produce recognizable breed-specific shapes. Through ablation studies, we find that our breed losses significantly improve shape accuracy over a baseline without them. We also compare BARC qualitatively to WLDO with a perceptual study and find that our approach produces dogs that are significantly more realistic. This work shows that a-priori information about genetic similarity can help to compensate for the lack of 3D training data. This concept may be applicable to other animal species or groups of species. Our code is publicly available for research purposes at https://barc.is.tue.mpg.de/.
Chained Representation Cycling: Learning to Estimate 3D Human Pose and Shape by Cycling Between Representations
Jan 06, 2020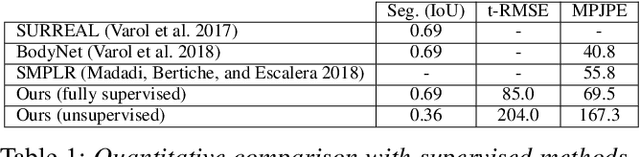
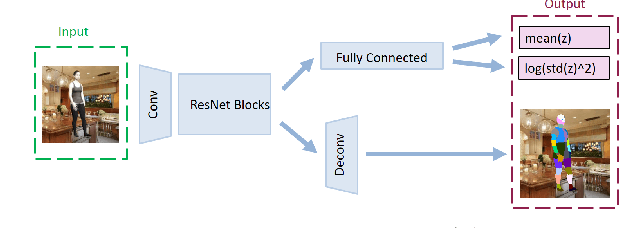
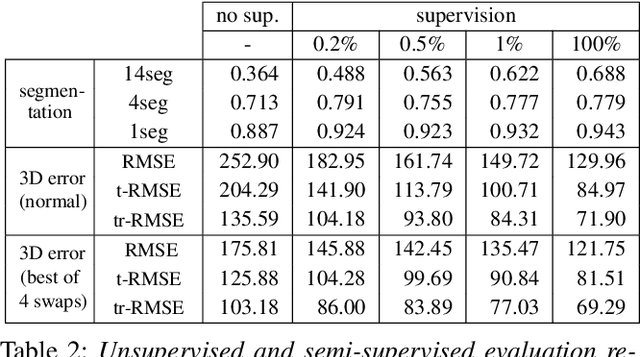

The goal of many computer vision systems is to transform image pixels into 3D representations. Recent popular models use neural networks to regress directly from pixels to 3D object parameters. Such an approach works well when supervision is available, but in problems like human pose and shape estimation, it is difficult to obtain natural images with 3D ground truth. To go one step further, we propose a new architecture that facilitates unsupervised, or lightly supervised, learning. The idea is to break the problem into a series of transformations between increasingly abstract representations. Each step involves a cycle designed to be learnable without annotated training data, and the chain of cycles delivers the final solution. Specifically, we use 2D body part segments as an intermediate representation that contains enough information to be lifted to 3D, and at the same time is simple enough to be learned in an unsupervised way. We demonstrate the method by learning 3D human pose and shape from un-paired and un-annotated images. We also explore varying amounts of paired data and show that cycling greatly alleviates the need for paired data. While we present results for modeling humans, our formulation is general and can be applied to other vision problems.